
Don’t bother: it is only a little expired
This story shows how we strive to fix issues reported by our customers regarding inconsistent listing views on our e-commerce platform. We will use a top-down manner to guide you through our story. At the beginning, we highlight the challenges faced by our customers, followed by presenting basic information on how views are personalized on our web application. We then delve deeper into our internal architecture, aiming to clarify how it supports High Availability (HA) by using two data centers. Finally, we advertise a little Couchbase, distributed NoSQL database, and explain why it is an excellent storage solution for such an architecture.
Later, we explain how the absence of adequate tools hindered us from uncovering the root cause of the problem and detail the adjustments we made in Couchbase to overcome these challenges. What can you glean from our experience? Firstly, you might be inspired to consider Couchbase as a storage solution in a multi-regional, active-active architecture. Secondly, you’ll discover a tool that aids in monitoring Couchbase behavior in a multi-region setting. Thirdly, we share some tips on manipulating settings in Couchbase. Lastly, you’ll be able to decipher the mysterious title of our story and understand a few technological abbreviations.
What you ask is NOT what you get #
An ongoing challenge in the development of the Allegro platform has been the product catalog. Originating from a C2C platform where offers lacked references to pre-existing products, our shift towards the B2C model brought forth the need to merge offers representing the same product. This was essential for enhancing the selection experience for our buyers. The journey to construct such a catalog involved various approaches, and after numerous iterations, it now functions seamlessly. For the context of this article, a crucial detail is that our platform must support at least two ways of selecting offers:
- Offer listing: Each presented entity is a unique offer listed by a particular merchant.
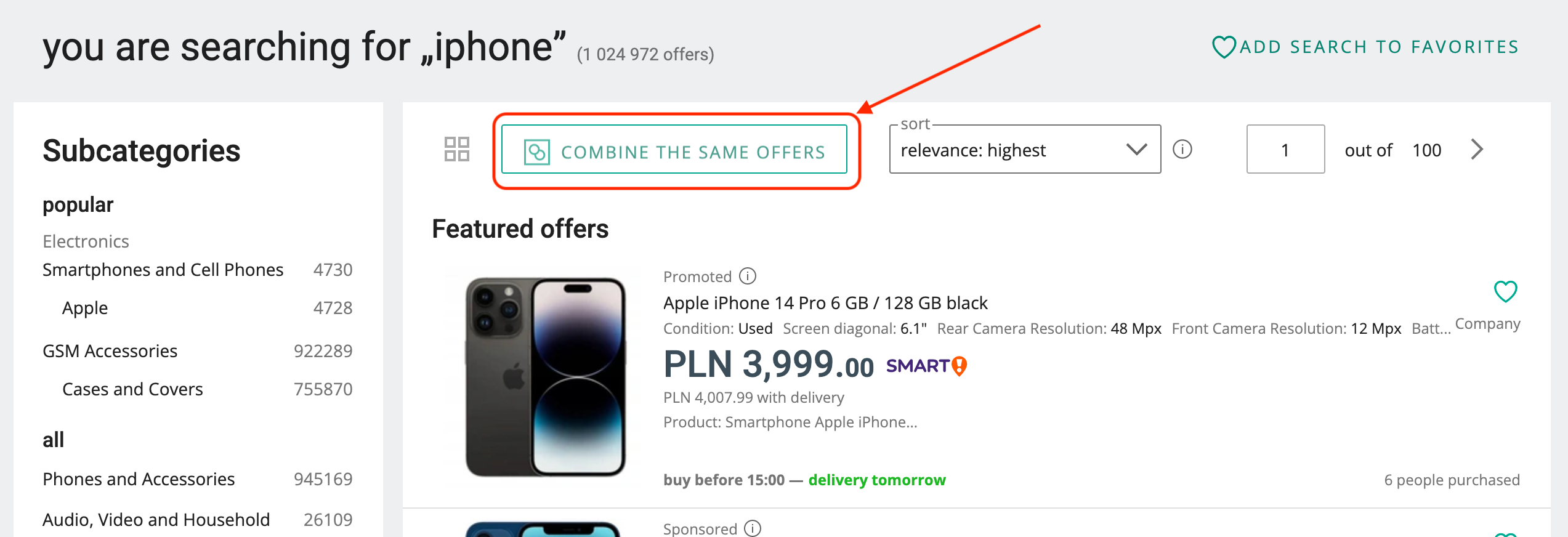
- Product listing: Each presented entity represents a unique product connected to a set of offers where you can make a purchase.
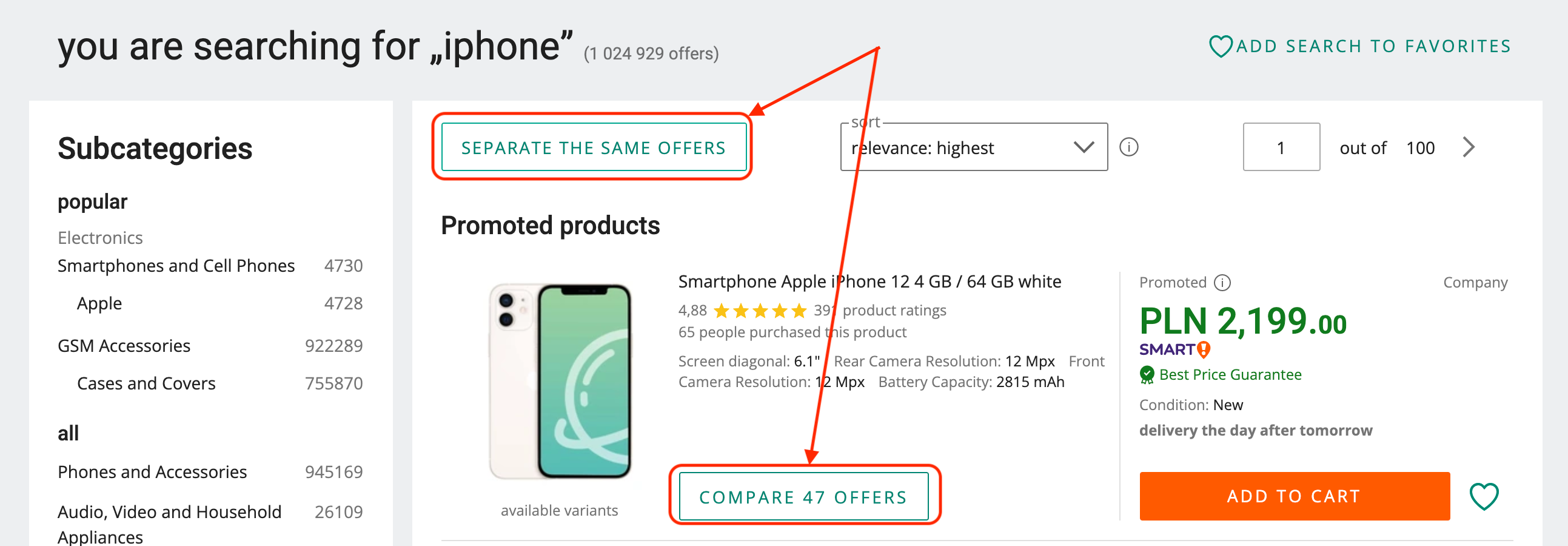
Given the diverse factors influencing whether a customer prefers selecting offers or products, we’ve deliberately avoided limiting the selection experience. In many cases, customers are free to choose either method, and their preferred choice is remembered to ensure a consistent and personalized experience. Both offer and product listing views feature a switch that allows users to change their personal preference. With each click, the personalized preference is updated, and the current view is refreshed accordingly.
However, our journey took an unexpected turn when we began receiving reports that customers, despite changing their preference, continued to see the same view. For instance, if a customer switched from the offer listing to the product listing, they would still receive the offer listing. The frustration escalated as this invalid view persisted, even after manual page refreshes, lasting several times before finally aligning with the customer’s preference after a delay, sometimes up to a minute. This discrepancy became the starting point of our investigation.
Remedy for rendering views in SOA - Opbox #
Dedicated readers of this blog may already be aware that the Allegro platform embraces a microservices architecture, a powerful strategy for dividing domains and responsibilities. However, this approach presents challenges when it comes to offering a unified graphical user interface (GUI) for our customers. To bridge this gap, we successfully implemented our internal Content Management System (CMS) platform named Opbox. While delving into the intricate details of Opbox is beyond the scope of this narrative, those interested in our frontend management can explore our blogpost or, if inclined, listen to our podcast in Polish here.
For our story, what’s crucial to note is that Opbox plays a pivotal role in fetching information from microservices, particularly about customer preferences. It collaborates with the microservice responsible for storing such data, ensuring the preparation of a personalized view for each user.
No detective skills were needed to deduce that the observed issues originated from the microservice responsible for storing customer preferences, which was serving outdated information. The real question at hand was how to mitigate this challenge.
Completing our narrative puzzle involves highlighting the interface familiar to our web application customers, which operates across two domains with distinct responsibilities:
- allegro.pl: This domain is responsible for providing the GUI (HTML views), rendered via Opbox.
- edge.allegro.pl: This domain takes charge of direct interactions via AJAX (Asynchronous JavaScript) with specific microservices.
In simpler terms, the listing view is rendered through the allegro.pl domain, while the task of switching personal preferences is handled via the edge.allegro.pl domain.
You can’t HAndle this #
As a member of the Technical Platform department, my perspective is likely biased towards High Availability (HA) and everything that enhances Allegro’s resilience to the outage of individual components or services. The fundamental principle guiding our HA strategy involves dispersing each microservice to two different locations, typically different data centers. This approach serves as a robust contingency plan, enabling us to overcome not only minor outages but also significant disasters, such as the outage of an entire data center.
It’s essential to note that our HA strategy operates on a multi-region active-active approach. In simpler terms, all our data centers or clouds are actively handling traffic simultaneously. While this approach ensures that everything remains operational in each location, it also introduces its own set of challenges. Balancing the benefits of simultaneous activity with the complexities it brings is a constant consideration in our pursuit of a resilient and fault-tolerant system.
Navigating the multi-region challenges #
Handling traffic in such a manner can undoubtedly impact performance. Each HTTP request from our customers typically involves a set of microservices. To mitigate the challenges of cross-datacenter traffic between these services, we introduced the principle of locality. In simple terms, if an instance of microservice A needs to communicate with microservice B, we prioritize instances running in the same location or data center.
However, it’s crucial to note that the locality principle faces limitations, especially when it comes to certain storage solutions. For instance, most Relational Database Management Systems (RDBMS) and MongoDB databases only allow writes through a specific node. This means that even if the traffic is handled by an instance in DATA CENTER A, it may still be necessary to query a database node in DATA CENTER B to write some data. The challenge lies in finding storage solutions that permit simultaneous writing to nodes in the same location. One such example is Couchbase clusters with cross-data center replication, offering a solution to the intricacies of our multi-region, active-active architecture.
Roots of inconsistency #
As mentioned earlier, we employ two domains to provide an interface for our customers. In the context of High Availability (HA), this setup implies that rendering can be handled by DATA CENTER A, while AJAX communication simultaneously takes place in DATA CENTER B. This dual-domain approach necessitates a replication mechanism that applies changes made in one data center to the other.
However, a critical challenge arises when the replication mechanism lags behind the Round-Trip Time (RTT) of client requests, as illustrated in the diagram below. The red rectangle in the diagram symbolizes the replication process of a single write operation. If this process takes longer than the back-and-forth exchange of HTTP response and request, the client may receive an invalid view. It’s crucial to note that the second request is directed straight to data center B and is not proxied by DATA CENTER A.
Mitigating this issue, short of radical architectural changes, becomes a significant concern. The intricacies of replication timing are central to ensuring a seamless and accurate user experience in our multi-data center, active-active architecture.
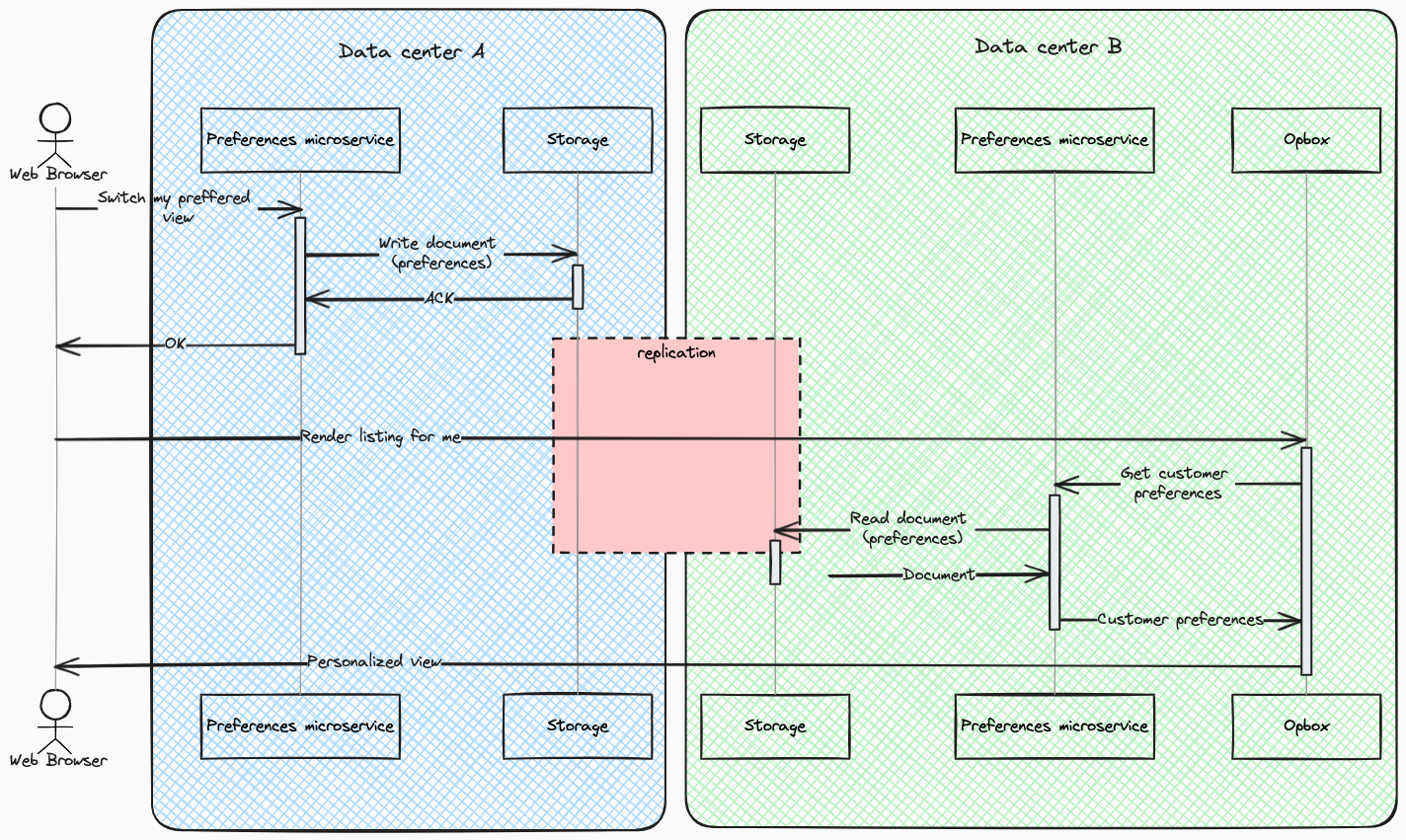
The replication lag can be influenced by various factors depending on the storage solutions in use. One undeniable factor is that it cannot be faster than the light distance between data centers. Fortunately, in our case, this distance is minimal, and for the purpose of this story, it can be considered negligible.
Fortunate storage #
As I mentioned earlier, Couchbase lends itself to adhering to our locality principle in the communication between microservices and databases within our architecture. Fortunately, it serves as the storage solution for the microservice responsible for maintaining customers’ preferences. What’s even more fortunate is the swift cross-cluster replication mechanism, XDCR, employed by Couchbase. In fact, the changes are applied on a cluster in the second data center faster than one Round-Trip Time (RTT) between data centers – pretty cool, isn’t it? It’s noteworthy that XDCR can be configured in either a unidirectional or bidirectional manner. In our case, given active-active writes in all locations, we use a bidirectional configuration to replicate changes, irrespective of the location in which they were applied.
Deeper analysis: unraveling the replication enigma #
Couchbase offers an abundance of highly detailed metrics regarding the internal state of the cluster. However, without a deep understanding, it becomes challenging to decipher whether irregularities or spikes in these metrics may indicate potential problems for customers. This challenge is particularly pronounced when dealing with cross-cluster replication, where overseeing the state of two clusters simultaneously is a complex task.
At Allegro, our commitment to meticulous data collection extends to being detailed in gathering performance metrics from a microservice perspective. Despite Couchbase providing meaningful information, the story would be incomplete if it solely relied on easily accessible metrics. In reality, these metrics failed to reveal relevant information; read/write times remained relatively stable even during moments when customers reported issues.
To gain a deeper understanding of the situation, our approach was clear—gather more data, with a specific focus on replication performance. This strategic emphasis on targeted data collection allowed us to delve into the intricacies of the replication process and uncover the underlying factors contributing to the challenges faced by our customers.
Measuring replication performance: the birth of cb-tracker #
Due to the lack of readily available tools and our inability to find suitable options, we took matters into our own hands and developed our open-source command-line tool, cb-tracker. This tool serves the purpose of continuously measuring replication lag. Its functionality revolves around connecting to two Couchbase clusters, designated as A and B, connected via XDCR replication.
The primary objective of our tool is to measure the Replication Round-Trip Time (RTT). In simpler terms, it gauges how quickly a document written to cluster A becomes accessible on cluster B, and vice versa. The logic behind this measurement is inspired by the widely used network diagnostic tool ping. To provide a clearer understanding of how this tool performs measurements, refer to the diagram below.
![]()
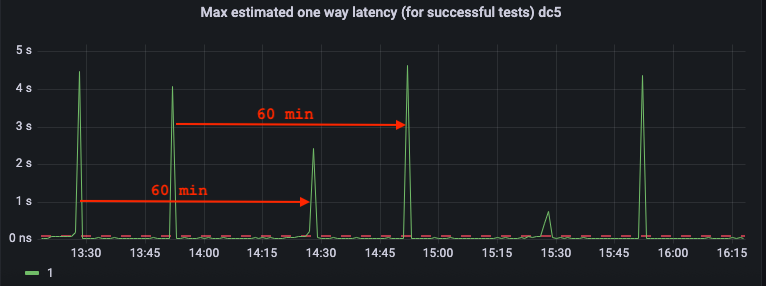
With the deployment of such a tool, we initiated continuous replication monitoring in the Couchbase bucket used by the microservice responsible for managing customer preferences. This monitoring effort provided us with valuable insights into the cyclic spikes in replication time. As depicted in the diagram below, we observed two spikes recurring every hour, about 20 minutes apart. This observation prompted us to investigate potential periodic tasks within Couchbase that might be contributing to this cyclic behavior.
There are my knobs: unraveling couchbase quirks #
While we’ve extolled the virtues of Couchbase, every solution has its quirks, and as the saying goes, the devil is in the details… and defaults :). In our case, the intricacy arose from the documents stored in the scrutinized bucket, each having a set Time-To-Live (TTL). The implementation of TTL on the Couchbase side is quite intriguing — expired documents are not deleted immediately; instead, they are skipped by the fetching logic. This situation could potentially last indefinitely, leading to storage consumption concerns.
To handle expired documents, Couchbase triggers a dedicated process every 60 minutes; the interval is controlled by exp_pager_stime parameter. Each run flushes out these expired documents from storage. However, an additional default setting — specifically, the flag filterExpiration indicating that each flush should be replicated via XDCR — created an unintended consequence. This default behavior caused a significant influx of events every hour, overwhelming XDCR. Consequently, other events, such as changes made by the microservice, had to be queued.
Understanding that this mechanism operates on each cluster and that every expired document would eventually be deleted, we recognized the need to address this overload of the replication mechanism. To rectify this, we adjusted the mentioned flag and increased the frequency of cleaning expired documents. Following this optimization, we observed a notable improvement, with no further instances of replication spikes.
Summary #
We grappled with a shortage of effective tools to monitor replication from a client perspective. As we’ve illustrated, pinpointing the genuine root cause of our problem was crucial. I hope that the tool we’ve introduced can also assist you in the ongoing quest for those valuable milliseconds.
Couchbase offers a comprehensive set of configuration parameters with default settings that might not be optimal for handling high-volume traffic. As demonstrated, there are subtle threats that can undermine the experience of an otherwise speedy replication mechanism like XDCR. It’s worth noting that our narrative is based on the community edition of Couchbase (v6), and it’s unfortunate that XDCR is withdrawn from the open-source version of Couchbase in the next release. I trust that our story can offer insights to help fine-tune your configuration and navigate potential challenges.