
Onion Architecture
Software Architecture is an elusive thing which, if neglected, can lead to a hard-to-develop and maintain codebase, and in more drastic circumstances to the failure of a product. This article discusses one of the backend application architecture styles which proved to be successful in providing a good foundation for building and maintaining an application in the long run: Onion Architecture.
Onion Architecture #
Onion Architecture is a software architectural style which strongly promotes the separation of concerns between the most important part of a business application — the domain code — and its technical aspects like HTTP or database. It does so with ideas similar to Hexagonal Architecture, Clean Architecture and other related architecture styles.
This post gives a description of the ideas of Onion Architecture and discusses a sample implementation which explicitly defines layers in the code and build setup.
Additional complexity to the build setup and extra learning curve introduced by the layered approach pays back during development. It reduces the cognitive load on the programmer by giving a more concrete structural foundation and guidance.
The Repository #
The code samples are taken from an example repository, which you can find on GitHub.
Why does Software Architecture matter? #
During my Engineering career, I’ve worked on multiple projects using different architectural styles. From a happy-go-lucky approach without any obvious structure, through “classic”1 three-tier enterprise style, to highly structured architecture, reflected by the setup of the build tool and supported by the compiler.
The experience of working on those projects was also very different. Having to introduce a change in a shapeless blob of spaghetti code was always a painful experience, connected with stressful moments of Have I broken something? Or Oh no! A gazillion of unrelated tests broke…
On the other hand, working in a more rigid, but at the same time more expressive, and structured environment of a well-architected application, was a breeze and a real pleasure. Not to mention that the time required to introduce the change was smaller, and the estimates were more precise and predictable.
Good architecture guides the implementation makes it easy to introduce new changes, and — to some degree — prevents less experienced team members from making doubtful decisions. It allows developers to focus on the value-providing implementation rather than thinking Hmm where should I put this class?.
Last but not least, software architecture is often defined as the things that are hard to change, so choosing a proper architectural approach to your new application is of key importance to its future development and maintenance.
About the Onion #
The idea of Onion Architecture, first introduced by Jeffrey Palermo in a series of articles, is similar to other clean architecture approaches presented in Robert “Uncle Bob” Martin’s blog post, his book Clean Architecture, and quite recently on our blog. It can be successfully used as an alternative to a popular Hexagonal / Ports and Adapters architecture, and as such is predominantly used in the backend, business applications and services.
The core concept in all the above styles is the same — to make the domain the most central part of the application, and remove all infrastructure concerns, such as talking via HTTP, messaging, database mapping, testing, etc., away from the domain code. The core of the business logic should be free (in theory at least) from any of the technical, and framework-related problems, allowing for easy testing and rapid development.
To put it using Uncle Bob’s words: Though these architectures all vary somewhat in their details, they are very similar. They all have the same objective, which is the separation of concerns. They all achieve this separation by dividing the software into layers. Each has at least one layer for business rules, and another for interfaces.
The main difference I’ve found in the implementations of Hexagonal Architecture and Onion Architecture lies mostly in
the overall, more structured approach to the code layout of the latter. Both styles rely on the conscious usage of
interfaces, and the Dependency Inversion Principle, which is the layer and encapsulation, but the Onion, like a real vegetable, has explicitly defined layers. Making the concept a
first-class citizen represented in the code guides implementation and gives more clear overall structure to the
codebase.
This Architecture style does have some learning curve for developers in the project, but once mastered, pays back many times. Finally, as with every solution in the IT industry, it is not a one-size-fits-all, and you should always consider if the architectural style matches your needs.
The Onion has Layers #
Onion Architecture is a form of layered architecture. The main difference between “the classic” three-tier architecture and the Onion, is that every outer layer sees classes from all inner layers, not only the one directly below. Moreover, the dependency direction always goes from the outside to the inside, never the other way around.
But wait, what are the layers of Onion Architecture, what do they describe, and why do they matter?
There are three2 main layers in Onion Architecture:
- The domain layer
- The application layer
- The infrastructure layer each of which has its responsibilities.
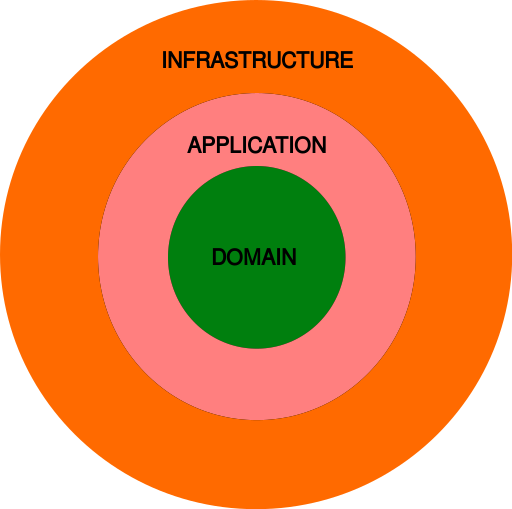
The Domain Layer #
This is the layer where you place classes describing the core of your business.
Let’s use a simple example. An application written to help manage a Library would most probably have classes like Book, Reader, Copy and so on. The classes, relations and interactions between them describe the core of the domain of the application, i.e. what business needs it fulfils and in what way. In the Library, there would be a process of adding new titles to the catalogue, a process of borrowing and returning copies of a book, charging readers for overdue books, and many more.
A sample domain class could look like the one below:
@ToString
@EqualsAndHashCode(of = "id")
@AllArgsConstructor(access = AccessLevel.PRIVATE)
abstract sealed class Book {
protected final BookId id;
protected final Version version;
protected final AuthorId author;
protected final Title title;
protected final CreatedAt createdAt;
protected final ApprovedAt approvedAt;
protected final RejectedAt rejectedAt;
protected final ArchivedAt archivedAt;
// static factory method for assembling a new instance of a Book — hides the internal representation
static Book create(AuthorId author, Title title, CreatedAt createdAt) {
return new NewBook(BookId.next(), Version.first(), author, title, createdAt);
}
// One of the subclasses representing the current state of the book entity
// Other subclasses omitted for brevity.
private static final class NewBook extends Book {
private NewBook(BookId id, Version version, AuthorId author, Title title, CreatedAt createdAt) {
super(id, version, author, title, createdAt, null, null, null);
}
@Override
protected BookSnapshot.Status status() {
return BookSnapshot.Status.AWAITING_APPROVAL;
}
@Override
Book approve(ApprovedAt approvedAt) {
return new ApprovedBook(id, version, author, title, createdAt, approvedAt);
}
@Override
Book reject(RejectedAt rejectedAt) {
return new RejectedBook(id, version, author, title, createdAt, rejectedAt);
}
}
// Available domain operations
Book approve(ApprovedAt approvedAt) {
throw new UnsupportedOperationException("Unsupported state transition. Cannot approve book in state [%s]"
.formatted(status()));
}
Book reject(RejectedAt rejectedAt) {
throw new UnsupportedOperationException("Unsupported state transition. Cannot reject book in state [%s]"
.formatted(status()));
}
Book archive(ArchivedAt archivedAt) {
throw new UnsupportedOperationException(
"Unsupported state transition. Cannot archive book in state [%s]".formatted(status())
);
}
}
Since the domain changes the most — here is the place where you put all the new features, and business requirements — it should be as easy as possible to modify and test. Thus, it should not be concerned which database is used in the project, nor should it know which communication style, synchronous RPC calls, asynchronous messaging, or a mix of is used to trigger the logic or maybe that it’s triggered by unit tests and not real user interactions. This doesn’t mean of course, that the domain classes can’t have any dependencies. Like it the example above — the code uses Lombok annotations, generating the boilerplate which otherwise needs to be written by the programmer.
The Application Layer #
This is the layer where you place your classes, which describe the use cases of the application and coordinate the work of the domain classes. For example, we can imagine that a new title added to the library undergoes an approval process: the book is fetched from the repository, a timestamp of approval is generated, the book state (only new books can be approved) is checked, and if it’s OK, a modified book is then saved using the repository.
The code describing such a use case can look like this:
class Books {
// other fields and methods omitted
public BookSnapshot approve(BookId id) {
return transactions.execute(() -> {
final Book book = bookRepository.getById(id);
final ApprovedAt approvedAt = new ApprovedAt(timeMachine.now());
final Book approved = book.approve(approvedAt);
return bookRepository.update(approved).snapshot();
});
}
}
This is also the layer that “knows” which operations should be performed atomically, thus the transaction-related code
is placed here. Note, however, that in the example above, the transactions field is actually an interface reference.
@FunctionalInterface
public interface Transactions {
<T> T execute(Supplier<T> operation);
}
The application uses the behaviour expressed by the interface, the details of how the behaviour is executed lie in the infrastructure layer.
The Infrastructure Layer #
This layer, the outermost layer of Onion, is a place where all framework and technology related stuff goes. It tends to be the most “thick” since it contains the implementations of the interfaces defined in the inner layers. Need an HTTP controller, a message listener or a database adapter (an implementation of repository interface defined at the domain layer)? Infrastructure is the place to go.
The domain, although the most important part of the application, tends to be also the smallest in terms of code size. The reverse is true about the infrastructure code — all the supporting mechanisms, which are placed at the infrastructure layer, are the backbone which animates the domain behaviour, and as such that part of the service should not be neglected.
Staying with the example of the Transactions interface, let’s take a look at possible implementations. A simple approach
using Spring’s programmatic transaction handling could look like this:
@Component
@AllArgsConstructor
class JdbcTransactions implements Transactions {
private final TransactionTemplate transactionTemplate;
@Override
public <T> T execute(Supplier<T> operation) {
return transactionTemplate.execute(status -> operation.get());
}
}
and for unit test, one can set up a fake, noop implementation:
class NoOpTransactionsFake implements Transactions {
@Override
<T> T execute(Supplier<T> operation) {
operation.get()
}
}
The Flavours of The Onion or how to represent layers in code? #
There are two basic approaches to representing the layers in the code. The one that we used in our most recent project was to use a package naming convention.

Every domain package has three subpackages: domain, application and infrastructure. This method is clear, easy to understand and navigate, and does not require changes to the build tool setup. The downside is that, except for the agreed convention, and Code Review process to check them, there is no mechanism preventing you from using a class defined in the application layer in the domain layer, thus breaking the direction of the dependencies. One can always use such tools as ArchUnit to write tests checking if there are no “prohibited” imports, but in my opinion, we can do better by employing build tool modules support.
Build tools to the rescue #
The more involved approach is to define compilation modules representing the layers. Its disadvantage is a more complicated build structure and setup of your build tool of choice. On the other side though, having the compiler on your side is very helpful, and prevents the above-mentioned issue. The direction of the dependencies between layers is clearly defined in the module build files.
// settings.gradle
rootProject.name = 'onion'
include('domain', 'application', 'infrastructure')
Using Gradle setup as an example, one can define three modules — domain, application, and infrastructure —
in settings.gradle file. Then, in the build files corresponding to each of the modules, declare their dependencies,
clearly defining the direction of dependencies.
// /application/build.gradle
dependencies {
implementation(project(':domain'))
}
// /infrastructure/build.gradle
plugins {
id 'org.springframework.boot'
id 'io.spring.dependency-management'
id 'com.revolut.jooq-docker' version '0.3.7'
}
dependencies {
implementation(project(':domain'))
implementation(project(':application'))
implementation('org.springframework.boot:spring-boot-starter-web')
implementation('org.springframework.boot:spring-boot-starter-jooq')
// other dependencies and settings removed for brevity
}
Notice, that the biggest file is the one for the infrastructure layer. It should not be a surprise by now. The infrastructure has all the framework — in this case Spring Boot — database driver, and other dependencies, and itself depends on both domain and application. There’s of course nothing preventing you from declaring extra dependencies, say Lombok. The most important thing to note here is that with this build setup, it will not be possible to reverse the order of dependencies between the layers.
Final Thoughts #
Problems Onion Architecture solves
- A more structured, layered layout of the code makes code navigation easier and makes the relationship between different parts of the codebase more visible at first glance
- Loose coupling between the domain and the infrastructure
- Coupling is towards the centre of The Onion — expressed by the relationship between the layers
- (Usually) No coupling between the domain and the infrastructure concerns of the application
- Build tool support in enforcing layers
Problems Onion Architecture creates
- Additional learning curve for new developers, and those used to other architecture styles
- Increased overall complexity of the codebase — especially with the flavour utilising the modularizing capabilities of build tools such as Gradle or Maven
- Not everyone likes the smell of it
As mentioned above at the beginning of the article, Onion Architecture is not a one-size-fits-all solution. It has its learning curve and is best suited for services with a clear domain definition. This makes it a bad choice, for more technical-oriented services, e.g. a high-throughput proxy written in a reactive framework.
Footnotes #
-
The typical, “classic” enterprise architecture, usually consists of three layers: the presentation layer, the domain layer and the persistence (data) layer. The dependency direction goes top-down, and in the strict approach a layer sees only its nearest neighbour. The clear advantage is the separation of concerns, and the reduction of the scope of responsibilities of each layer. There are two issues though — that architecture style often leads to a so-called anemic domain model, since most of the business logic is placed in service classes, because, and that’s the second issue, domain classes depend on the persistence layer — and often become only data carriers without behaviour. For a comparison of different software architecture styles, see Software Architecture Patterns (e-book, pdf) ↩
-
The number of layers may differ. The three-tier division is usually called Simplified Onion Architecture. Another possible rendition of the division is to have five layers with a separate Repository layer above the domain and a service layer above the repositories. I find that division to be a step towards over-engineering and found that the 3-layered approach strikes the best balance. ↩