

Exploring GraphQL’s performance tradeoffs
At Allegro we decided to introduce GraphQL as our API Gateway for building several internal client systems. By building such a solution we’ve learnt a lot about this technology and we would like to share it with you in this article.
What’s GraphQL and how does it work? #
To understand how to increase GraphQL’s performance we need to understand how it works under the hood. Why is it so important? In GraphQL most of the common ideas on how to speed up the communication are useless. One of the things we usually do is introduce caching to our application, but you can often hear that GraphQL is not cacheable. Indeed it is not that simple in GraphQL and we hope to clarify it to you later in this article.
So what is GraphQL? GraphQL’s documentation says:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more […].
GraphQL sends the information through a standard TCP connection (mostly HTTP). There is only one entry point and all needed information is sent in a request parameter or body. In contrast to the REST API, where we often fetch fields that we won’t use, in GraphQL we can ask for and compute only the useful ones. This key feature gives us the first and most important way to speed up our application: ask only for the information that you need.
There are three key concepts that we should be aware of:
- Schema — description of your data in a JSON-like format.
type User {
id: ID
name: String
email: String
friends: [User]
}
- Queries — the way we ask for processing information. We provide information about which resources we want to fetch or mutate and which fields exactly we want to be returned. We can fetch data with an operation called a query or change data with a mutation. Below we query for the user’s name and his friends’ names.
query {
user(id: "1234") {
name
friends { name }
}
}
- Resolvers — fragments of code that serve information for specific parts of schema.
Resolver design is a game changer! #
We will spend the whole paragraph on making sure we are on the same page understanding how resolvers work. A schema consists of types definitions: — defined queries/mutations/subscriptions that we can ask (we can think of it as the root of the graph) — input objects that we take as arguments in queries/mutations/subscriptions — objects that we return from queries/mutations/subscriptions — scalars, the simplest types like int or string (which are always a leaf in a graph)
As the schema is composed of queries and types, there are two kinds of resolvers. The first is obligatory and resolves the whole query. It can return the complete result, but also only a part of it. The second part is added by type resolvers. Let us show you an example: let’s say we want to get information about a user.
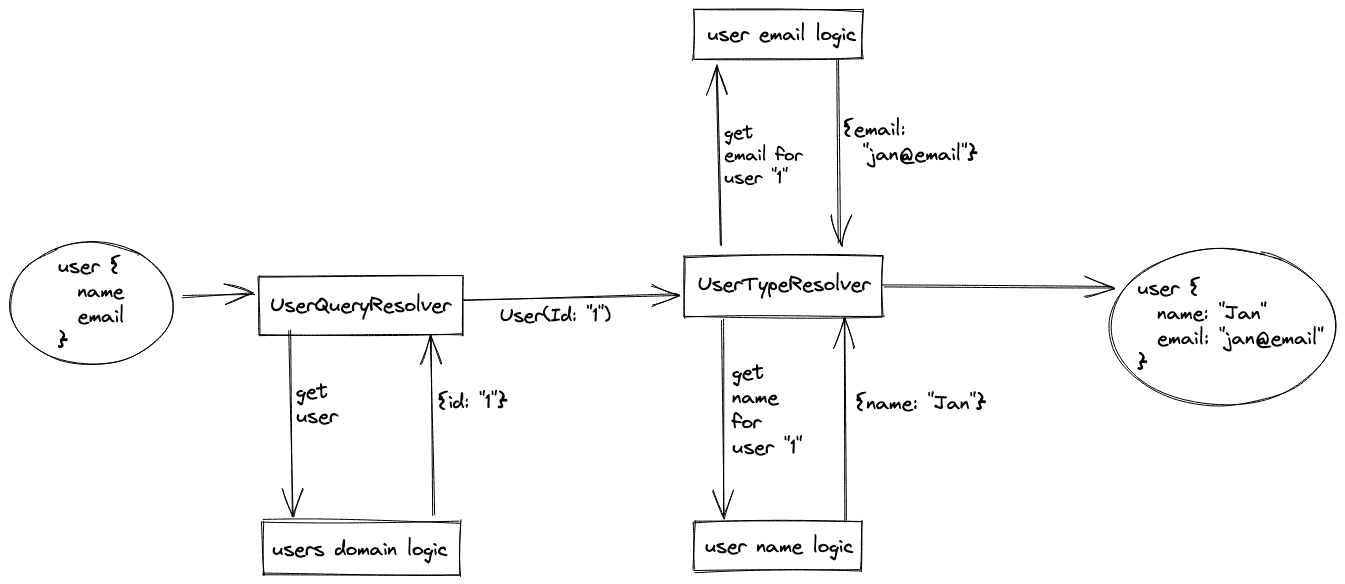
At first we run UserQueryResolver, which fetches user data from user domain logic. Only the ID of the user is returned.
Then we call UserTypeResolver with the ID resolved earlier.
It makes two calls: first one to user email service and second to user name service.
When resolving is over, GraphQL returns the result.
UserQueryResolver might also have returned all information.
One of the main questions about optimizing GraphQL is when to use a query resolver, and when a type resolver.
We decided to use:
-
A query resolver for fields that come from the same data source as the identifier field. We may ask for information that we don’t need, but we skip the unnecessary connection time overhead when we ask for more than one field. Moreover, most of the sources that are connected to our service are REST APIs and always compute all fields, so why shouldn’t we use them? Adding additional resolvers also complicates logic and makes the flow less clear.
-
A type resolver when some parts of a query can be resolved independently, because those parts can run in parallel. To achieve it, wrap the resolver’s functions with any of the asynchronous abstractions. We also use type resolvers when we ask for some part of the domain that isn’t ours to avoid dependency crossing.
The metrics war #
There are different approaches to performance monitoring depending on the element whose performance we monitor:
- Poor - HTTP endpoint (just one endpoint which always responds with 200 status code)
- Better - GraphQL query/mutation (each query/mutation)
- Almost great - Resolvers (access to data source)
The HTTP endpoint is the point at which we measured performance for a REST API. For example one of the simplest ways of monitoring performance for API endpoints is response time. Some basic dashboards could look like this:
In the GraphQL universe, there is usually only one endpoint. This approach has advantages and disadvantages. While we have low latency and no errors it is great for us as developers and business. We have just one entry point and one failure point but if something goes wrong we have to dig deeper.
The chart below, showing p95 response times for a single GraphQL endpoint, does not tell the whole story. In reality we have plenty of consumers which use different input data and ask us for variety of payload in extended scope.
We are using a simple metric configuration for measuring endpoints:
class MetricFilter(
private val meterRegistry: MeterRegistry
) : OncePerRequestFilter() {
override fun doFilterInternal(
request: HttpServletRequest,
response: HttpServletResponse,
filterChain: FilterChain
) {
val start = System.nanoTime();
try {
filterChain.doFilter(request, response)
} finally {
val finish = System.nanoTime();
meterRegistry.timer(
"api.execution",
"statusCode",
response.status.toString(),
"path",
request.requestURI
).record(finish - start, TimeUnit.MILLISECONDS)
}
}
}
Remember that our queries can change in time, e.g. by extended business requirements. They can start from a simple query like this:
query {
user {
id: ID
name: String
email: String
}
}
After a few new features are added, they can end up more complex like the one below. In the same query we ask for ten thousand additional objects from another data source.
We can imagine that the previous p95 dashboard doesn’t have much value now because it is perfectly normal that the
computation time increases when we ask for additional data. The pagination plays a big role here, too.
Both of these queries can still be executed at the same time and shouldn’t be measured by the same metric.
query {
user {
id: ID
name: String
email: String
friends(limit: 10000, offset: 1){
name: String
lastName: String
}
}
}
Slow query log #
After integrating a huge number of new APIs we realized that simple HTTP endpoint monitoring was not enough in our case. We had been looking for a better approach. Slow query log is a simple concept - set a threshold at which we consider a query too slow. Each query that exceeds that threshold gets logged with all input parameters. Moreover we set up metrics which indicate that some problematic query appears. Is such an approach perfect? No, we still have to analyze each query and answer the question if the query is slow because of query complexity or maybe because of other problems. At the end of the day we can use this approach as a simple and effective tool to find slow queries quite fast.
As an example we can show you the code below. We created our own instrumentation at the beginning of each query to measure time and variables.
@Component
class MonitoringInstrumentation(
private val clock: Clock,
private val meterRegistry: MeterRegistry,
) : SimpleInstrumentation() {
override fun instrumentExecutionResult(
executionResult: ExecutionResult,
parameters: InstrumentationExecutionParameters
): CompletableFuture<ExecutionResult> {
try {
val instrumentationState = parameters.getInstrumentationState<MonitoringInstrumentationState>()
val startTime = instrumentationState.startTime
val endTime = getTime()
val executionTime = startTime - endTime
if (executionTime > 1000) {
val query = parameters.query
val variables = parameters.variables
metric.increment(
SLOW_QUERY_METRIC_NAME,
"duration",
executionTime)
logger.warn {
"Slow query: $query with variables ${serializeVariables(variables)}." +
" Duration: ${executionTime.toMillis()} ms"
}
}
}
return super.instrumentExecutionResult(executionResult, parameters)
}
}
Per field monitoring #
Last but not least, an interesting approach which we consider, and is almost out of the box for resolvers and supported by many libraries, is per field monitoring.
It is pretty nice for getting extra data to analyze our graph.
However, it can be expensive to collect such a type of data.
Gathering metrics for each field can be more valuable than monitoring each query.
Moreover, we can easily find the bottleneck of bits and pieces of our graph.
Resolvers monitoring can be achieved by using libraries built into our GraphQL server implementation such as
graphql-java-server.
Our implementation follows the Apollo proposed tracing format (A community building flexible open source tools for GraphQL).
{
"data":
"user": {
"name": "Javier",
"friends": [
{
"name": "Clarisa"
}
]
},
"extensions": {
"tracing": {
"version": 1,
"startTime": "2022-04-14T23:13:39.362Z",
"endTime": "2022-04-14T23:13:39.497Z",
"duration": 135589186,
"execution": {
"resolvers": [
{
"path": [
"user"
],
"parentType": "Query",
"returnType": "Character",
"fieldName": "user",
"startOffset": 105697585,
"duration": 79111240
},
{
"path": [
"user",
"name"
],
"parentType": "Girl",
"returnType": "String",
"fieldName": "name",
"startOffset": 125010028,
"duration": 20213
}
]
}
}
}
}
Bottom line of resolver monitoring is thinking about it as checking each data source, not the internal mechanism of GraphQL implementation. It is possible that our internal performance is not the limiting factor as I / O and external connections are often critical.
Batching requests to external services #
In the paragraph about resolvers we mentioned connecting to the same source many times to fetch all the type fields in case of using type resolvers. There is a solution for that, and it is called data loaders. How does it work? It collects all requests from many parts of the schema and retrieves their data in one request. This allows it to solve the N+1 problem, which is very well known in GraphQL. Imagine the situation where we want to query for three users.
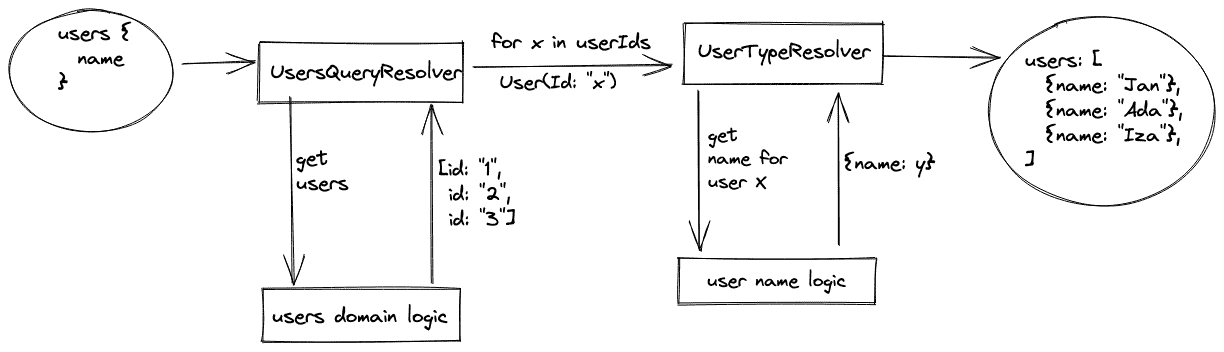
As the diagram says, we must ask external sources four times for three users – once to fetch all users and once per each user to fetch his name. Moreover we call user name service many times even if it has some batch method to get logins for many users. Introducing a data loader solves this problem. The second diagram shows how it works.
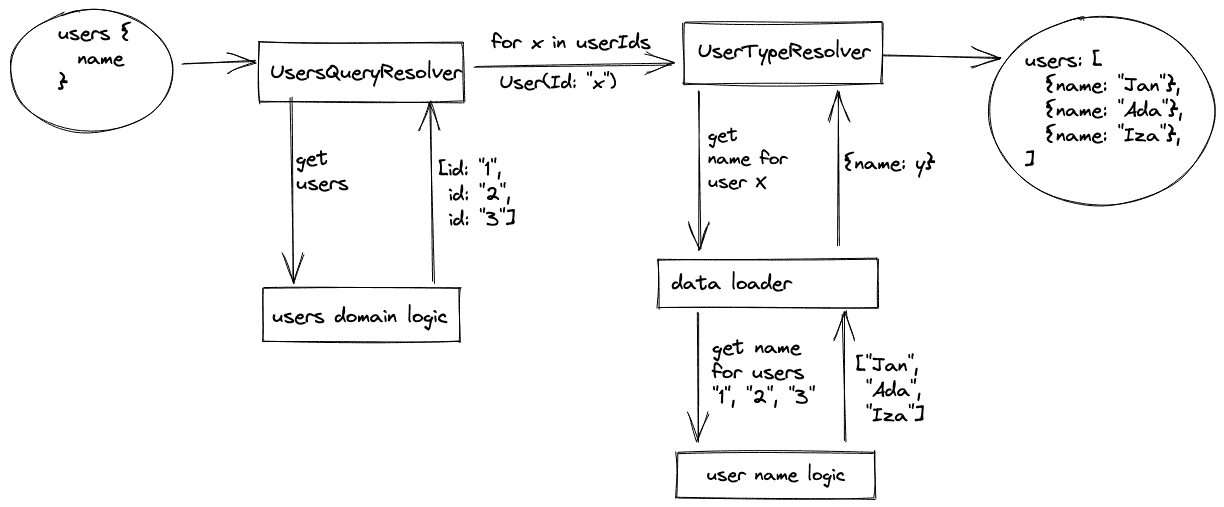
We cumulate all requests and ask user name service only once. Let’s see what the code looks like.
We have UserBatchDataLoader which asks userClient for users and maps the response to User object.
@Component
class UserBatchDataLoader(
userClient: UserClient,
executor: Executor
) : BatchDataLoaderInfo<String, UserResponse, User>(
{ userIds -> userClient.users(userIds) },
UserResponse::userId,
{ it.toUser() },
executor
)
There is also UserTypeResolver that uses it while resolving user name.
class UserTypeResolver(
private val userBatchDataLoader: UserBatchDataLoader
) : GraphQLResolver<User> {
fun name(
user: User,
dfe: DataFetchingEnvironment
): CompletableFuture<String?> =
extractDataLoader(userBatchDataLoader, dfe)
.load(user.userId.raw)
.thenApply { it?.name }
}
Exactly the same can be done with User fields in the type resolver.
We can accumulate requests for each field and run it once if the source is the same.
There is a UserDataLoader that asks UserClient for the whole User object.
@Component
class UserDataLoader(
userClient: UserClient,
executor: Executor
) : SimpleDataLoaderInfo<String, UserResponse>(
{ userId: String -> userClient.user(userId) },
executor
)
It is used in UserTypeResolver while resolving first name and email.
@Component
class UserTypeResolver(
private val dataLoaderInfo: UserDataLoader,
private val executor: Executor
): GraphQLResolver<User> {
fun firstName(user: User, dfe: DataFetchingEnvironment): CompletableFuture<String?> =
extractDataLoader(dataLoaderInfo, dfe)
.load(user.userId.raw)
.thenApply { it?.person?.firstName }
fun email(user: User, dfe: DataFetchingEnvironment): CompletableFuture<String?> =
extractDataLoader(dataLoaderInfo, dfe)
.load(user.userId.raw)
.thenApply { it?.contacts?.email }
}
Caching - why is it so troublesome? #
HTTP caching #
The biggest problem that makes using HTTP caching less effective is plenty of different requests that we can make. When we ask for a user with his name and email the response is saved in cache. But when we ask again without the information about email despite the fact that the information is already available we cannot use it, because this is a different query (and HTTP cache cannot handle it without understanding GraphQL logic). To make cache work best we should recognise at field level which user name is already in memory and ask only for the rest of them.
Server-side caching #
Let’s put aside HTTP caching and focus more on how we can implement server cache that is more focused on GraphQL logic. We could cache specific types from our schema or their fields. A good example of implemented server-side cache is apollo-server. So if we run the same type or query resolver with the same arguments it can be returned from cache. With data loaders you can also cache requests to external sources not only in one query, but even between many queries by selecting a specific strategy. This solution is available out of the box, and can be used easily.
Client-side caching #
Another common way to cache query response is client-side caching. It can be very beneficial, because one client may ask for the same information many times. As an example we can take Apollo client and its solution. The cache uses the ID field to identify whether an object exists in memory. Then it checks if all fields that are to be returned are already in memory, if some are not it asks only for them.
Our caching decisions #
We’ve decided not to use server-side caching with a global data loader because we have struggled with many clients of our graph and the graph’s data
changes frequently. That forced us to use a cache-per-request strategy.
If we are talking about caching on the client side we tackle the issue that some of our objects don’t have a unique ID so after a while we skipped this approach and we are not caching them on the client side either.
What is the outcome of the battle? #
We have learned a lot about GraphQL’s trade offs while working with it, but there is still a lot to be discovered. The most important feature of it, fetching only those fields that we need, is a huge optimization itself, but also causes many problems with standard ways to make the application effective or even to measure that efficiency. The ideas that we described above need to be implemented by the programmers (most libraries don’t provide that logic) and it’s really complex and time consuming.