
Comparing MongoDB composite indexes
One of the key elements ensuring efficient operation of the services we work on every day at Allegro is fast responses from the database. We spend a lot of time to properly model the data so that storing and querying take as little time as possible. You can read more about why good schema design is important in one of my earlier posts. It’s also equally important to make sure that all queries are covered with indexes of the correct type whenever possible. Indexes are used to quickly search the database and under certain conditions even allow results to be returned directly from the index, without the need to access the data itself. However, indexes are not all the same and it’s important to learn more about their different types in order to make the right choices later on.
What’s the difference? #
I’ve had a conversation with a colleague of mine the other day, about the point of using composite keys in a MongoDB database. I’ve always been a firm believer that it’s a good idea to use a composite key wherever possible because searching this way is very fast. My colleague, on the other hand, advocates using artificial keys and creating separate composite indexes on fields for which I would use a composite key. After a brief disagreement, I realized that other than my intuition, I had no arguments to defend my beliefs. I decided to see how indexes on composite keys differ from composite indexes created on regular fields in practice.
As an example for our considerations, we will use an entity describing a person by first and last name, let’s also assume that this pair is unique.
Such data can be stored in a collection (let’s call it composite) with a composite key that contains both fields.
{
"_id" : {
"name" : "John",
"surname" : "Doe"
}
}
A unique index will be automatically created on pair of both fields along with the collection.
Many developers would most likely prefer to use an artificial key, and index the name and surname fields
separately, as shown in collection artificial:
{
"_id" : ObjectId("615eb18b76e172647f7462e2"),
"name" : "John",
"surname" : "Doe"
}
When it comes to the second model, only the artificial key will be automatically covered by the index. To be able to efficiently search the collection by first and last name, we need to manually create a composite index on both fields. To maintain consistency with the first collection, of course, uniqueness also needs to be enforced:
db.artificial.createIndex({name: 1, surname: 1}, {unique: true})
At first glance, we can clearly see that the first way of storing data is more compact, since we only store two fields
of interest, and only one index is required in addition to the data. For the second collection, in addition to the data
itself, we need to store an artificial key, moreover two indexes are required here: on the artificial key and on
the name and surname fields.
We can now move on to comparing the execution plans of queries to two collections, so let’s take a look at the result
of the explain commands:
db.composite.find({
"_id" : {
"name" : "John",
"surname" : "Doe"
}
}).explain("executionStats")
and:
db.artificial.find({"name" : "John", "surname" : "Doe"}).explain("executionStats")
Let’s start with the second result first. We can see that the optimiser chose to use the index we manually created.
{
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"name": 1.0,
"surname": 1.0
},
"indexName": "name_1_surname_1"
}
}
}
[…]
{
"executionStats" : {
"executionSuccess": true,
"nReturned": 1
}
}
In the case of a collection with a composite key, however, the plan is different; it contains the word IDHACK:
{
"winningPlan": {
"stage": "IDHACK"
}
}
[…]
{
"executionStats" : {
"executionSuccess": true,
"nReturned": 1
}
}
It means that the optimiser skipped the index selection phase (although in our case there were no other indexes, but it doesn’t matter) and decided to use the key index. This operation is considered to be the fastest one possible. Whenever there is a key in the query, its index will be used (while ignoring conditions on other fields).
Let’s also take a look at the notation "nReturned" : 1, which means that both queries returned a single document.
We already know that queries to both collections will be handled with an index. However, I’ve been wondering if there are any differences between these indexes?
The first should be search time: since whenever there is a key in the condition list, its index will be used, theoretically, key’s index should be the fastest. We’ll get to that topic in a moment. For now, let’s see what happens if we only want to search one field at a time:
db.getCollection('composite').find({
"_id" : {
"name" : "John"
}
}).explain("executionStats")
db.getCollection('artificial').find({"name" : "John"}).explain("executionStats")
In the case of the first query, the index was admittedly used, but we got no results, as evidenced by the notation:
{
"executionStages": {
"stage": "IDHACK",
"nReturned": 0
}
}
This happens because a composite key requires all its components to be used by the query, so it is impossible to search by a single field.
The situation is different when querying the second collection, here the index was also used, however this time the document was found:
{
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"name": 1.0,
"surname": 1.0
},
"indexName": "name_1_surname_1"
}
}
}
[…]
{
"executionStats" : {
"executionSuccess": true,
"nReturned": 1
}
}
What if we decide to search by surname only?
db.getCollection('composite').find({
"_id" : {
"surname" : "Doe"
}
}).explain("executionStats")
db.getCollection('artificial').find({"surname" : "Doe"}).explain("executionStats")
In a collection with a composite key, we have a situation similar to the previous one - the index was used, but we didn’t receive any document. The reason, of course, is the same: we didn’t use all the key fields.
By querying the collection with a separate composite index, we got the document we were looking for, but it turns out that this time the index was not used, and instead the database had to search through the entire collection:
{
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"surname" : {
"$eq" : "Doe"
}
},
"direction" : "forward"
}
}
This is because with composite indexes, while it is possible not to use all indexed fields, it is only permissible to skip values in the reverse order, that is, reading indexed fields from the right. Our index was created on the fields in the following order:
db.artificial.createIndex({name: 1, surname: 1}, {unique: true})
It is therefore possible to omit the condition on the surname field and search only by name, but it’s not possible
the other way around.
We managed to find out the first difference between two types of indexes: composite key indexes are less flexible, require all values to be specified, while in regular composite indexes we can omit values from the right.
Let’s also check if the order of conditions matter?
db.getCollection('composite').find({
"_id" : {
"surname" : "Doe",
"name" : "John"
}
}).explain("executionStats")
db.getCollection('artificial').find({"surname" : "Doe", "name" : "John"}).explain("executionStats")
And here’s another surprise: even though all the components of the key were provided, but in reverse order, the first query did not find the document.
{
"executionStages" : {
"stage": "IDHACK",
"nReturned": 0
}
}
With a regular composite index, the optimiser was able to reverse the field order itself and use the appropriate
index to find the document: "nReturned" : 1
{
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage": "IXSCAN",
"keyPattern": {
"name": 1.0,
"surname": 1.0
},
"indexName": "name_1_surname_1"
}
}
}
For the time being, indexes on composite keys are losing against regular ones. This is a good time to get back to the
question about the search time of the two indexes. Now that we’ve established that indexes on composite keys are less
flexible, it’s a good idea to figure out what we gain in return for such limitations. We already know that IDHACK
skips all indexes and always uses a key, so one might think that this is the fastest available way to get to the
document. I decided to check this on my own.
It’s time to experiment #
I filled both previously used collections with 10 million documents. I used the following scripts for this purpose:
var bulk = db.composite.initializeUnorderedBulkOp();
for (let i = 0; i < 10000000; i++) {
bulk.insert({_id: {name: 'name_' + NumberInt(i), surname: 'surname_' + NumberInt(i)}})
}
bulk.execute();
var bulk = db.artificial.initializeUnorderedBulkOp();
for (let i = 0; i < 10000000; i++) {
bulk.insert({_id: new ObjectId(), name: 'name_' + NumberInt(i), surname: 'surname_' + NumberInt(i)})
}
bulk.execute();
It is worth noting here that I’m adding documents in batches. This is definitely faster than a list of single inserts
and is useful when we need to generate a large amount of data quickly. Also note that I am using existing collections
so my index on name and surname fields already exists.
I measured the execution time of both scripts using following commands (to avoid network latency I performed the measurements on my laptop, with a local instance of MongoDB version 4.4.0 running):
time mongo test fill1.js
time mongo test fill2.js
Filling collections with documents took 58,95s and 76,48s respectively. So when it comes to insert operation time,
the composite key collection clearly wins. The reason for this, of course, is a simpler document structure and only one
index, instead of two.
I was more interested in read times, because in a typical case, data is usually read more often than written. For each collection,
I prepared a script containing a list of find commands for 1 million documents in random order. Of course, the order of
queries in both scripts is the same:
#!/bin/bash
RANDOM=42
for i in {1..1000000}
do
x=$(( $RANDOM % 10000000))
echo "db.composite.find({_id: {name: 'name_$x', surname: 'surname_$x'}})"
done >> find1.js
#!/bin/bash
RANDOM=42
for i in {1..1000000}
do
x=$(( $RANDOM % 10000000))
echo "db.artificial.find({name: 'name_$x', surname: 'surname_$x'})"
done >> find2.js
Finally, I measured the execution time of both scripts using the commands:
time mongo test find1.js
time mongo test find2.js
The results surprised me. The script running on the first collection took 11.19s and the second took 10.15s. Although the differences are small, I was sure that using a composite key would be much faster than searching through regular fields and would make up for all the inconvenience of less flexible keys. Meanwhile, it turns out that a collection built with an artificial key and a separate index on two fields wins in terms of search speed.
I had one more idea. Maybe searching a document by a key that doesn’t exist would be faster? To test this, I generated another two scripts, this time searching for non-existent documents:
#!/bin/bash
RANDOM=42
for i in {1..1000000}
do
x=$(( $RANDOM % 10000000))
echo "db.composite.find({_id: {name: 'missing_name_$x', surname: 'missing_surname_$x'}})"
done >> find-missing1.js
#!/bin/bash
RANDOM=42
for i in {1..1000000}
do
x=$(( $RANDOM % 10000000))
echo "db.artificial.find({name: 'missing_name_$x', surname: 'missing_surname_$x'})"
done >> find-missing2.js
Unfortunately, the composite key collection also lost in this case: 12.44s vs. 10.26s.
Finally, I decided to run one more test. Since when using composite key we have to pass the entire key to the query and cannot search by its fragment, I decided to create a third collection, this time its key being the concatenation of first and last name:
var bulk = db.concatenation.initializeUnorderedBulkOp();
for (let i = 0; i < 10000000; i++) {
bulk.insert({_id: 'name_' + NumberInt(i) + '-' + 'surname_' + NumberInt(i)})
}
bulk.execute();
I then prepared another script containing 1 million search operations (in the same order as the previous attempts, of course):
#!/bin/bash
RANDOM=42
for i in {1..1000000}
do
x=$(( $RANDOM % 10000000))
echo "db.concatenation.find({_id: 'name_$x-surname_$x'})"
done >> find3.js
This time I was finally able to get a result better than the one achieved with the artificial key approach: 9.71s. All results are summarized in the chart below:
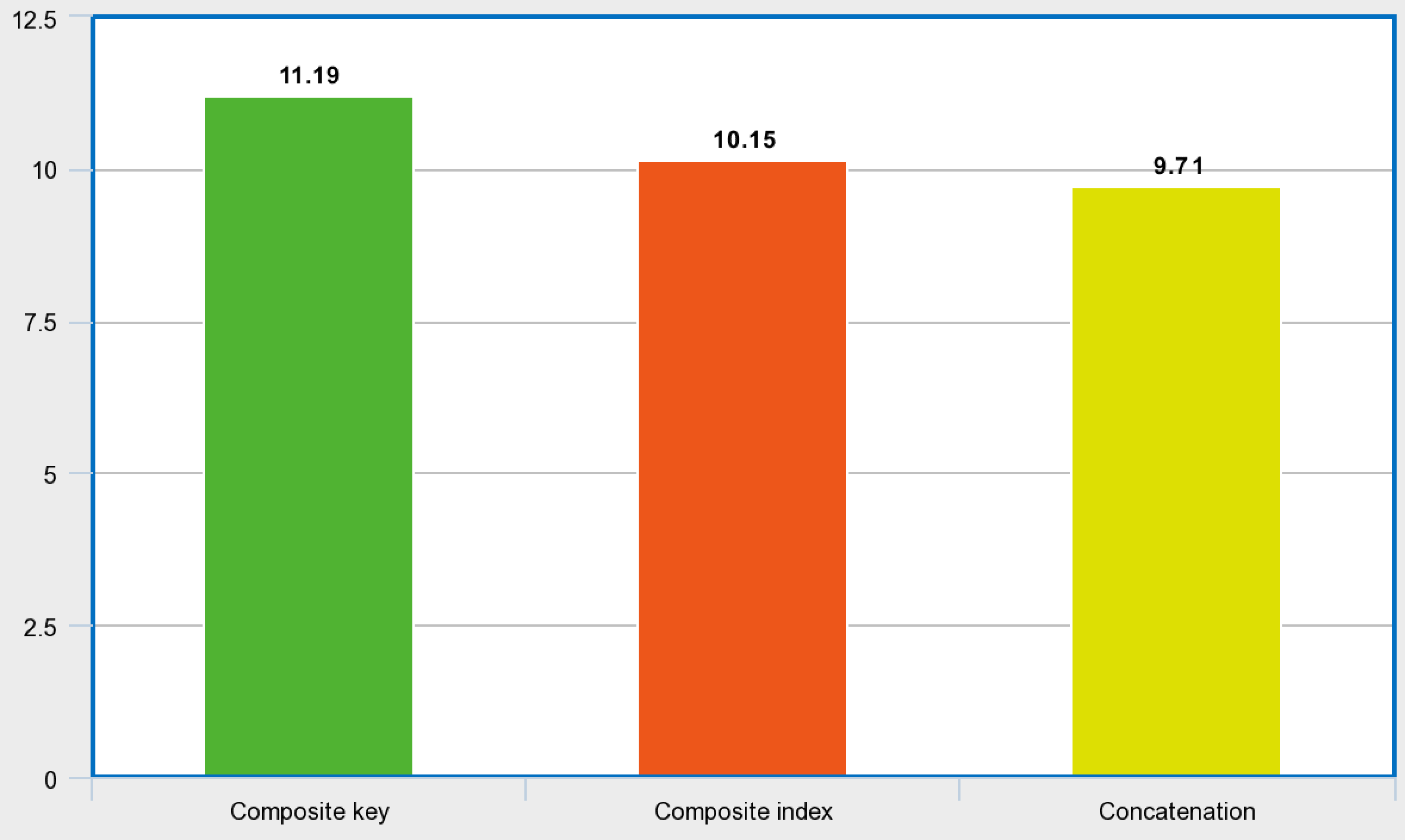
Conclusion #
It appears that the IDHACK operation is indeed the fastest possible way to access a document, but only for a simple
key. As soon as we add an additional field into the key, the benefits of the IDHACK operation disappear and the
regular index works better.
In general, my experiments did not confirm the advantages of using a composite key. The artificial key model is more flexible in querying and returns results faster. However, if you want to search even faster, you may consider using a simple key created by concatenating selected fields.
I realize, of course, that I did not use the latest available version of the mongo server. For this reason, I am posting all the scripts I used in my attempts and encourage you to experiment on your own. Perhaps composite keys perform better in newer versions of the database?