
How to efficiently write millions of records in the cloud and not go bankrupt — an Azure CosmosDB case study
Cloud providers like to brag about high availability and unlimited scaling of their services – and they are correct, as these features are indeed significant advantages of cloud solutions. Their computational power is so high that for most use cases, it’s almost unlimited. In this blog post, I would like to tell you about our experiences with Azure Cosmos DB and batch processing.
Our story #
At Allegro Pay we are taking advantage of Azure’s no-SQL database, Cosmos DB. It does a great job when it comes to handling operations on individual records — let’s say, fetching specific user’s data or modifying it. But what if we wanted to change the status of 10 million users based on some external analytic query? What’s more, we want it neither to last a couple of hours nor to cost us a little fortune. Actually, we may even want to run such operations on a daily basis.
In this blog post, I want to focus on the technical aspect of this challenge rather than diving deep into the business scenario. So let’s specify our technical requirements explicitly:
- The overall time of such a batch operation cannot exceed 5 minutes per 1 million records.
- The processing cannot starve other operations that are being run on the database at the same time. The batches will be executed from time to time, but the database still needs to be able to handle regular traffic that is generated by users’ requests.
- The solution must be cost-effective. The problem with the cloud is not making a solution that is scalable and fast, it’s making it so at a reasonable price. All these features that cloud providers brag about do come at a cost.
- The solution must be scalable to handle the increasing size of the database. Today we are talking about writing 10 million records, but if in one year we will be writing 100 million, all these requirements should still be met — of course, not at an exponentially higher price.
The outcomes of this case study are published as an open source repository (see Our library).
Cosmos DB — the basics #
Before going into detail, let’s look at the basic concepts of Cosmos DB. If you are familiar with this service and its provisioning modes, you may want to jump directly to the Database utilization chapter. As already mentioned, Cosmos DB is a no-SQL database available in the Azure cloud. Some of its core features are unlimited automatic scaling and guaranteed read and write latencies at any scale (source). If we compare them with the previously set requirements, it seems like Cosmos DB is a perfect choice. It scales automatically, so the database should scale itself up during batch processing. Besides, the “guaranteed latencies” feature may suggest that the response times should not increase under heavy load, and the processing should be fast.
How does it look in reality? Let’s take a look at a quick experiment. I created the most naive implementation of a batch update process. Its pseudocode may look like this:
foreach record
{
Item = CosmosClient.Get(record.ID)
ProcessChange(Item)
CosmosClient.Update(Item)
}
For each batch record, we first fetch it from the database, then execute some logic that modifies it, and at last, save it in the database. The Cosmos’ API is quite simple, allowing us to perform simple atomic operations, such as getting a record by an ID, updating, inserting etc. It also allows querying through multiple APIs, such as SQL, MongoDB, Cassandra, Gremlin or Azure Table API, which is out of this document’s scope.
What’s the result of executing this code? It processed 50k records in about 10 minutes. This doesn’t seem too long, but if we estimate the time needed to process a million records, that would be more than 3 hours. Or even worse, if we think about processing tens or hundreds of millions, it becomes almost impossible. But that’s not all — looking at the Cosmos DB metrics, I noticed that the database utilization was as low as about 6%. To explain what exactly it means, I will first talk about how Cosmos DB scales and how it calculates the costs.
Cosmos DB — scaling and provisioning #
Cosmos DB uses so-called Request Units to calculate resource utilization. They represent a normalised operation cost in terms of CPU, memory and IO needed to execute the request. This way, we don’t need to care about physical (or virtual) machines that are being used or their parameters — the database size and the operation costs are always expressed in RUs. Microsoft estimates a single read operation of a 1KB item as 1 RU and other operations’ cost correspondingly more.
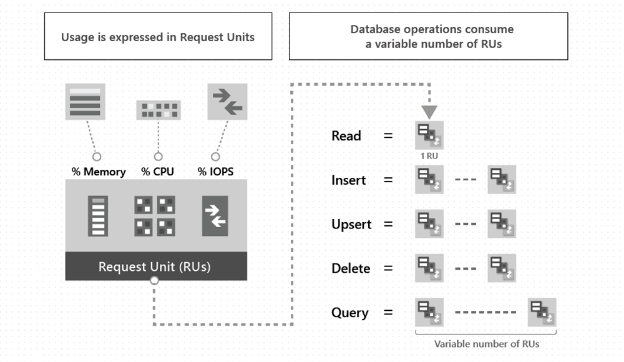
Source: https://docs.microsoft.com/en-us/azure/cosmos-db/request-units
But what does “correspondingly more” mean exactly? Microsoft does not precisely define this as it depends on multiple factors — such as item’s size, index configuration, query complexity, etc. We do not know how many RUs the operation will consume until we actually execute it. Luckily, every response from Cosmos DB contains the operation’s cost inside the headers. What’s more, RU consumption is quite repeatable. For example, if one write operation has previously cost 5 RUs, and we execute the same request on a similar item, we can presume that it will also cost 5 RUs. Of course, it may change in time — along with the increasing database size, RU consumption may also increase.
At this point, the question is: how do all these affect the price of the service, and how many of these RU units are we actually able to use? Cosmos DB offers us three so-called provisioning modes, which determine how Azure scales the database and bills us for the consumed resources.
Manual #
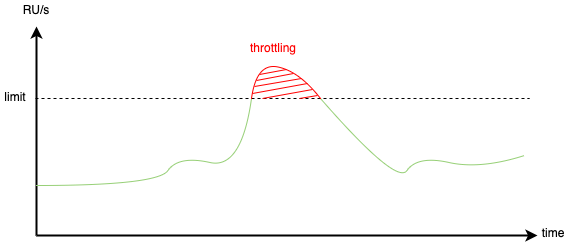
In the manual mode (aka “provisioned throughput”), we declare how many RUs we are going to consume per second — the higher we set this limit, the higher the price. The minimal value is 400 RU/s which converts to around 20 euros per month. This can be increased at any time if needed, but we will pay more. The billing is per hour, so we pay for the highest configured value during a single wall-clock hour.
What happens if we try to exceed this declared value? Some of the requests will be rejected with HTTP status code 429 (Too Many Requests) — Cosmos DB will throttle the traffic so that the actual sum of the consumed RU in each second does not exceed the configured limit.
Autoscale #
The second mode is autoscale. As the name suggests, it will automatically scale based on the current load, that is, the actually consumed RUs, but not higher than the configured limit. To be precise, autoscale mode can scale the database up to 10 times. For example, if we configure the max autoscale limit to 4000 RU/s, then the basic available RU limit will be 400 RU/s, which converts to 20 euros per month. If we try to consume more, it will automatically scale up to 4000 RU/s, which converts to 200 euros per month. The bill at the end of the month will range between 20 and 200 euros, depending on how many times and how much the database needed to scale.
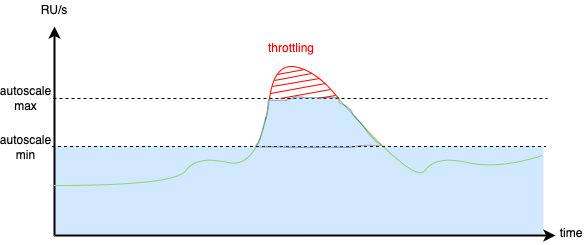
What’s the catch? We can easily set the max autoscale throughput to any value we want, but we will not always be able to return to the previous value. In fact, we can only decrease it to 1/10 of the maximum value we ever set. For example, if we set the database to autoscale in the range of 6k-60k RU/s, the lowest we can go back with is 600-6k RU/s.
Nevertheless, this mode sounds quite promising. As the requirements state, we want to put a high load on the database from time to time without affecting other processes. It seems that autoscale mode can be useful for this use case.
Serverless #
The last mode is serverless. It’s rather straightforward — at the end of the month, we pay for the exact number of RUs that we have consumed. No need to declare anything, no need to scale. A million RUs cost around 25 euro cents. This may sound tempting. We can calculate how much it costs to process a million records, estimate how many we process during a month, and when we put it together, it may look like the final price is not even very high.
Unfortunately, if we read the docs, we can find some additional information:
- The maximum storage for the Serverless Cosmos DB is 50 GB. For a big production database of a high-scale service, such as Allegro Pay — it is simply not enough.
- The guarantees for the operation latencies are worse — 30ms instead of 10ms.
- Serverless mode is incompatible with High Availability settings and cannot be replicated in another Azure region.
- Moreover, the maximum throughput during a single second is 5000 RUs.
As we can see, the more we learn about the Serverless mode, the more evident it seems that it’s not intended for applications in production. Even Microsoft suggests that this mode is best suited for the development or test databases and new services with low throughput.
To sum up, Cosmos offers us three interesting options when it comes to scaling that seem pretty simple to use. But if we dig deeper, there are quite a few catches.
Database utilization #
Let’s go back to the sample code I was running.
Foreach record
{
Item = CosmosClient.Get(record.ID)
ProcessChange(Item)
CosmosClient.Update(Item)
}
It processed 50k records in about 10 minutes. How loaded was the database?
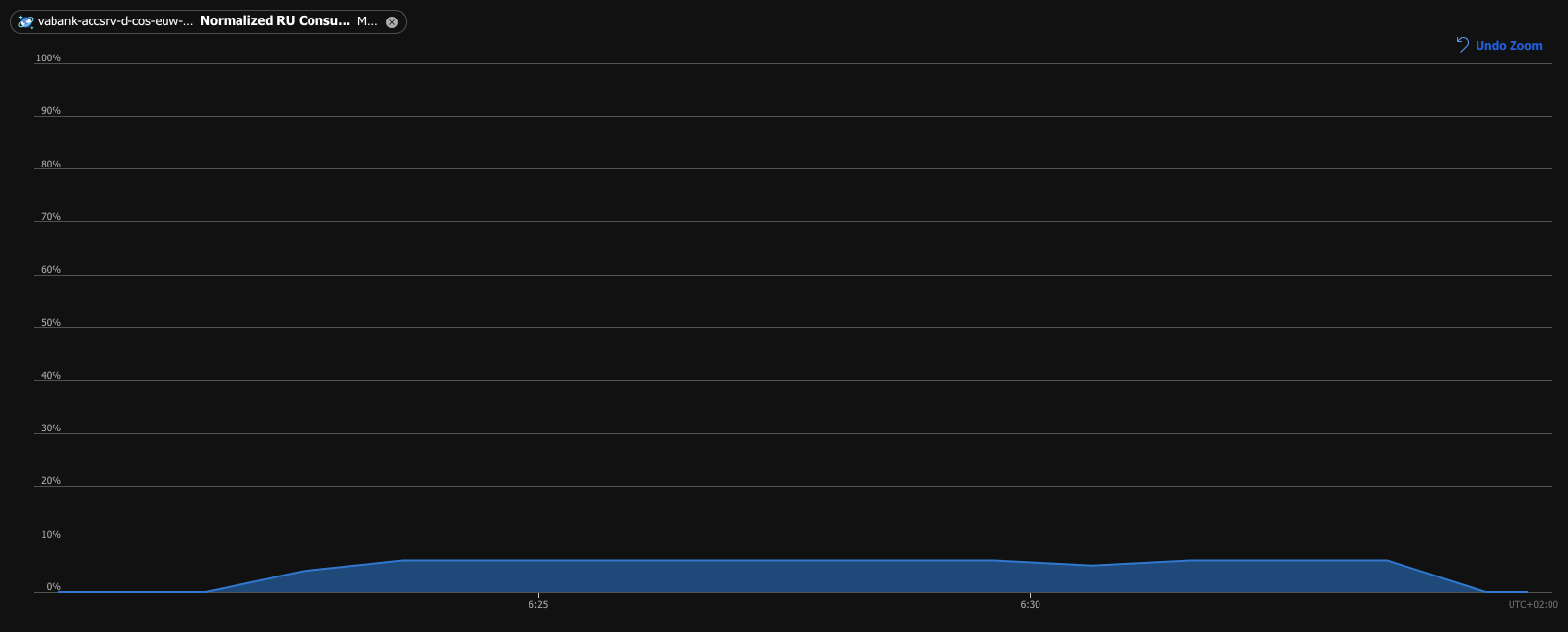
Normalized RU Consumption shows the percentage of the database load, which at this time was scaled up to 4000 RU/s. Its utilization was only around 6% during the batch processing. It’s a bit low and it obviously could take more load.
If we look back at the code I was running, it’s easy to see that it’s lacking one important thing — parallelism. The operations are executed one after another synchronously, which makes it impossible to fully utilize the database. Sending the requests in parallel is a simple optimization that obviously comes to mind. Let’s see what happens if we run the code with parallelism added.
This time, with the database scaled up to 40k RU/s, the processing of 1 million records took 8 minutes. What’s more, the database utilization was reaching 100%. This may look very promising, but hang on a minute — running at 100% database usage means that we are on the edge of throttling. I checked the logs and it actually happened — some of the requests were being throttled and retried. What if some other operation would try to access the database in the meantime, for example customer’s purchase process? It could easily be throttled and rejected or at least delayed by the retries.
RU limiter #
Is there anything we can do to make this solution fulfil the previously set requirements? Let’s think about it. We know how many RUs we consume (Cosmos DB is providing this information in the response headers), and we know how high we scaled the database… Then why not try and precisely control the flow of outgoing requests, aiming at a specific RU/s usage? This is what we have done at Allegro Pay — we have built our own RU limiter, as we called it. In order to do that, we implemented a simple counter that tracks RUs consumed in a given interval. Using this counter, we can limit the outgoing requests so that RU limit is not exceeded in any second, but instead wait until the next second before releasing the queued requests.
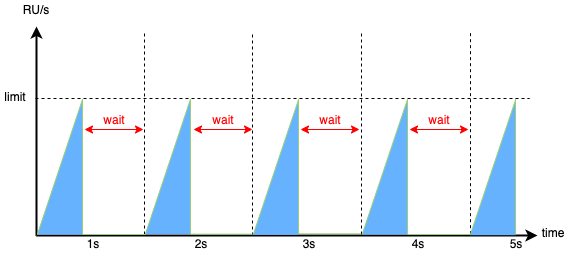
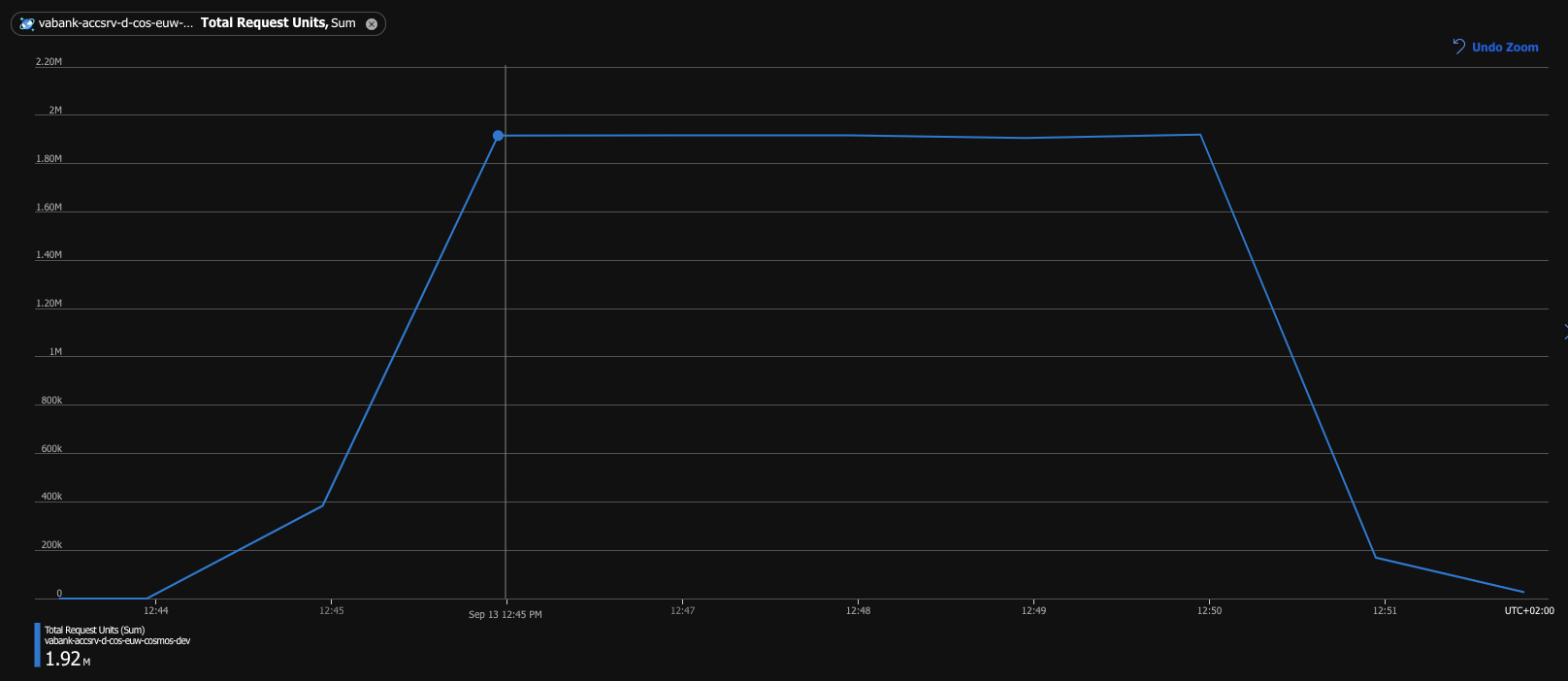
The mechanism sounds pretty simple, doesn’t it? And here is how it worked. I ran another test, this time with RU limiter set to 32k RU/s. Although the requests were being limited, the processing of 1 million records took only 5 minutes this time and no request was throttled. Below we can see the Total Request Units metric during the test. The consumption was almost precisely 1,92 mln RU / minute, which gives us 32k RU/s — exactly as the RU limiter was configured.
Partition key ranges #
It almost looks as if we could wrap up and call it a day. But let’s take another look at the Normalized RU Consumption metric.
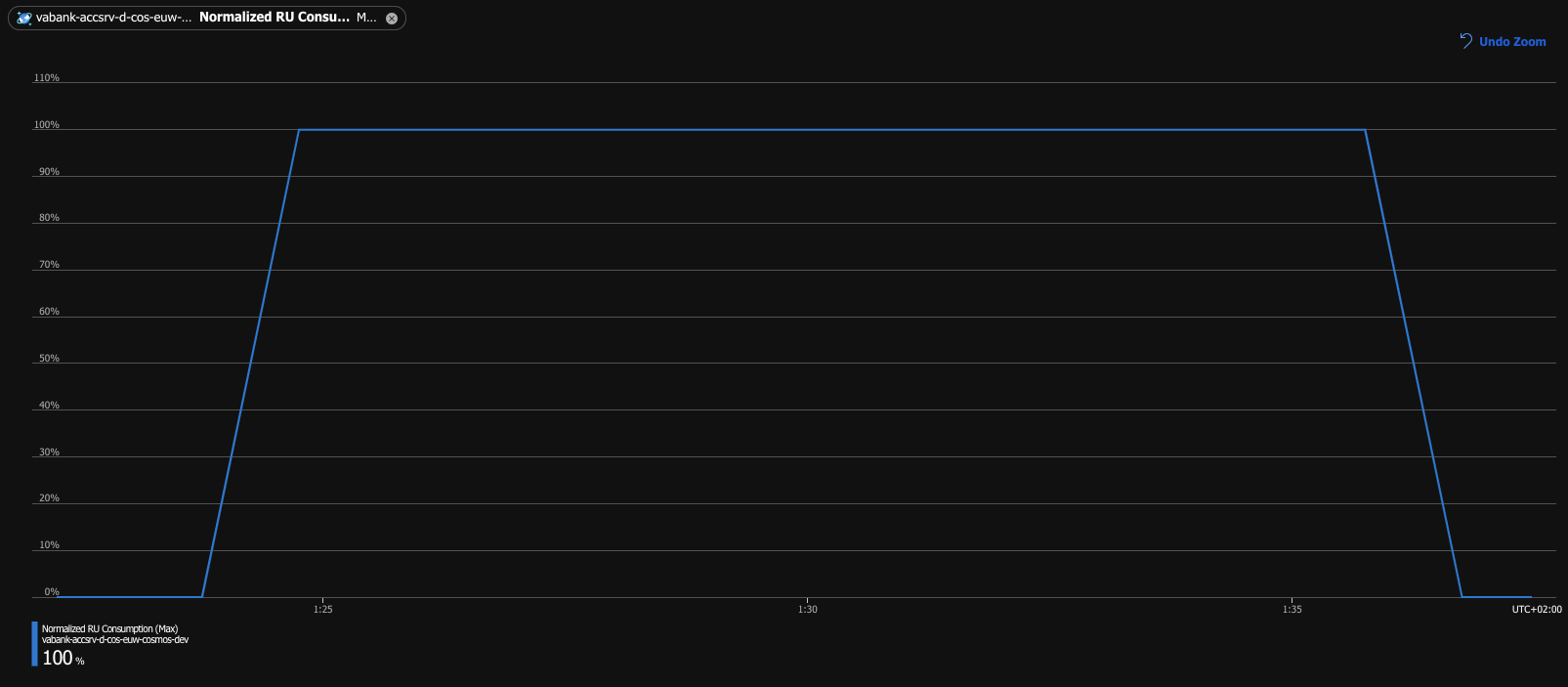
Something is not right here. With the database scaled up to 40k RU/s and the consumption rate of precisely 32k RU/s
(confirmed with the Total Request Units metric), the database utilization should be around 80%, not 100%. What exactly
is happening here? If we dig deeper into the documentation or just look around the metrics, we could discover something
called PartitionKeyRangeId. And what is the partition key range? Every item stored in a Cosmos DB collection has its
PartitionKey — a key used by Cosmos to partition the data. In our case, that could for example be an Allegro user
identifier. The partition key passed to the API is hashed, so that the distribution of partition keys is even. As the
database grows, Cosmos DB automatically splits it into partitions. It does it using the partition key ranges — items
from each range make up a physical partition. The problem is that these ranges are not always of equal size — they usually
are, but there are periods when Cosmos has just split some of the partitions, but has not yet split others. Below is
the Normalized RU Consumption metric split by partitions.
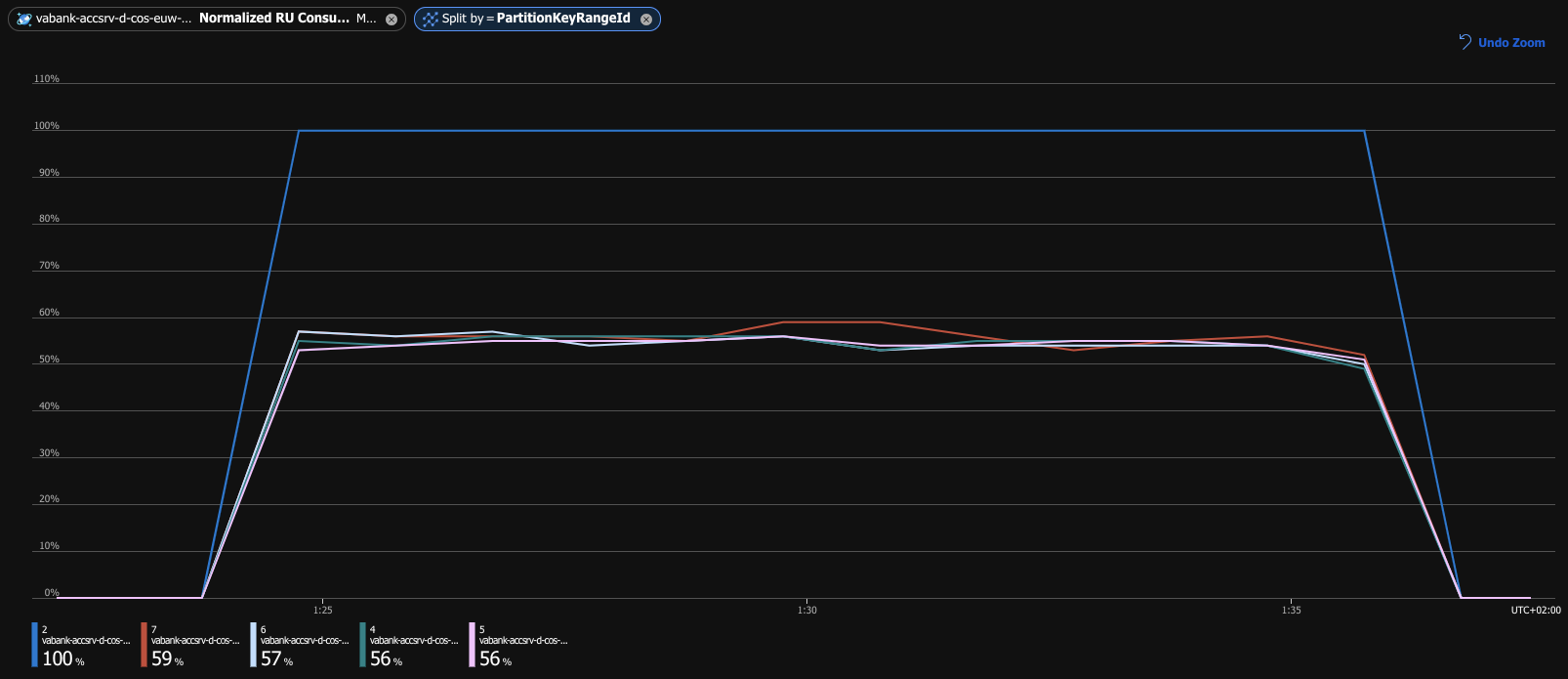
If we dig into the documentation even further it turns out that the 40k RU/s that we configured as the provisioned throughput is equally split between the partitions — even if their sizes are not equal. Odds are that even if we consume up to 40k RU/s in total, we are still overloading some of the partitions. If at that moment we received a request from a customer whose ID falls into that partition key range, the request could be throttled.
A bit of reverse engineering #
Is there anything that could be done to limit RU consumption per partition? Well, technically yes. If we knew the partition key hashing mechanism that Cosmos DB is using and knew the exact partition ranges that our database is currently split into, we could count the RU limits not per the whole database, but per each partition. The good news is that this is indeed possible, as the hashing is done on the client side, inside the CosmosDB SDK, which is open source. The bad news is that probably we don’t want to do that, except maybe out of academic curiosity. In fact, I implemented such a partition-based RU limiter and it worked like a charm. But would I use that in production? Absolutely not. Copy pasting and making a dependency on some internal implementation of the database, which may change at any time (well, probably with some backward compatibility, because that would also break the SDK) does not sound like a production-ready solution or something that my colleagues at Allegro Pay would approve in a code review.
The “Autoscaler auto scaler” #
The problem of the uneven partition key ranges persists, but is there any decent solution? Well, probably just one — to scale the database so far up, that we always have some RUs buffer. If we use autoscale mode and set the Max Autoscale Throughput high enough, we may on one hand not overpay during periods when the partition distribution is uneven, and on the other hand, not risk overloading some of the partitions when it happens.
The one last catch is that, as already mentioned, Cosmos DB in autoscale mode can only scale up to 10x. If we configure the Max Autoscale Throughput to 60k RU/s, then the lowest it will scale down is 6k RU/s, costing us at least 300 euros a month, and every processed batch tops the bill up. Is it much for a company such as Allegro? Probably not, but let’s say we do not have a single database like that, but tens, maybe even hundreds? It turns out the game is worth it.
But what if we increase the Max Autoscale Throughput value up to 60k RU/s only just before the batch processing has started? This is exactly what we did. Fortunately, Microsoft has given us the possibility to change the max throughput using not only the Azure Portal, but also through the API. This way we can automatically scale up when the batch is starting, and scale back down when the batch processing has finished. All we need to remember is that after rising the Max Autoscale Throughput, we can only go 10x lower. If we scale up to 60k RU/s — we can go back just to 6k RU/s Max Autoscale Throughput (meaning Cosmos will be scaled in range of 600-6000k RU/s).
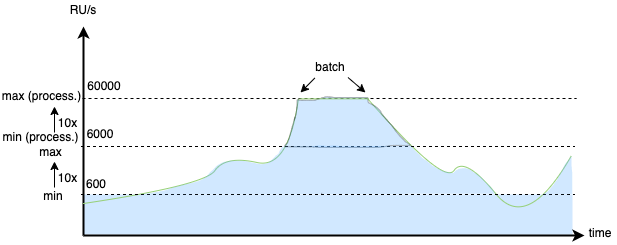
With this one simple trick, we created an “Autoscaler auto scaler”, as we automatically scale the Cosmos DB’s Autoscaler range and achieve in turn the possibility to scale 100x times instead of just 10x. When the traffic on the database is at its minimum, we operate at just 600 RU/s, and during the batch processing, we go up to 60k RU/s, maintaining a buffer high enough that there is no risk of throttling.
This way, we have fulfilled all the requirements that were set at the beginning:
- Batch processing time — 5 minutes per 1 million records.
- No risk of starving other processes, thanks to the RU limiter.
- Cost-effectiveness — thanks to the developed autoscaler we only pay for what we actually need.
- Scalability — we can easily scale the solution up by scaling the database and if needed, also the number of batch processing service replicas. Although this will eventually increase the minimal throughput we can go back to, but with the increasing scale, the minimal traffic on the database will also grow — and we can scale even 100x.
Our library #
The outcomes of this work have been published as an opensource .NET library on our GitHub page: Allegro.CosmosDb.BatchUtilities. Feel free to use it or even contribute new features.
Conclusions #
And here we are, at the end of the story. We have reached the intended goal, but there were a few plot twists and surprises on the way. To sum it up, I would like to point out a few aspects of working with Cosmos DB or with almost any cloud service in general:
- Cosmos DB (and the cloud in general) gives predictable costs as long as we get time to know it and study the documentation. Sometimes we may even need a PoC or some quick experiment because the documentation does not say everything or is not precise.
- Cosmos DB gives precise control over the database scaling, but again — we need to get to know how exactly it works first.
- You must pay close attention to the costs, as it is very easy to get high bills by misusing the service.
- It’s worth making data-based decisions — do the PoCs, and experiments and watch the metrics. This is exactly what we did here to get to the final and optimal solution.