
How to make context logging in Python less cumbersome
This post is about the reasons behind writing a small (yet practical) library that has just been released as open-source: LogExtraCtx
Why did I write this library? #
I’m a big fan of logging. I like to log as much extra data as possible, and I’m
fond of logging.debug entries.
I’m also a DRY approach believer. I feel strong anxiety when I see repetition in code.
And my mind literally hangs when I need to do Ctrl-C/V, even if it’s justified by
circumstances. In such cases I start to focus on getting rid of copy-pastes instead of
writing new code.
Combining all these “passions” is not always easy. It’s hard to log everything without repeating things. Even if it’s possible, it usually leads to inelegant code.
For example, if you want to log that some error occured:
logger.error('Foo happened: %s', e)
Then so far it’s clean and easy.
It would be nice to add some extra details though, like user
(then you could search by user in Kibana, if your logs goes there):
logger.error('Foo happened: %s', e, extra={'user': user,
'action_type': 'bar'})
Next, during debugging of a problem, you will notice that it’s not nearly enough and it’s worth
adding some logging.debug
logger.debug("We're going to do SOMETHING in thread",
extra={'user': user,
'action_type': 'bar',
'thread_num': thread_num})
After that you will notice that your code has extra= with duplicated user and action_type.
It’s a Bad Thing! Imagine what would happen if there was another logger.debug, and another?
Lots of repeated code that should be written only once…

So in other words, the more details you log, the more cumbersome the code. What can we do?
Method 1: don’t log extra #
It’s not what I like. I do want to log them!
Method 2: store extra in a variable #
It’s what I used to do sometimes, before LogExtraCtx. It could go like that:
extra = {'user': user, 'action_type': 'bar'}
logger.debug("We're going to do SOMETHING in thread",
extra=dict(thread_num=thread_num, **extra))
logger.error('Foo happened: %s', e, extra=extra)
Quite tricky and not very elegant.
Method 3: use LogExtraCtx #
Before I describe the aforementioned library, let me show you a more realistic example.
Consider the following code:
logger = logging.getLogger(__name__)
def send_message(requester: str, recipient: str, text: str) -> bool:
""" Function send_message sends message to the specified recipient. """
try:
r = requests.post(settings.MSG_PROVIDER, json={'recipient': recipient, 'content': text},
... < other params > ....)
r.raise_for_status()
except requests.exceptions.RequestException as e:
logger.error('Sending message failed. Response text: "%s"', e,
extra={ # extra data to be logged and indexed by Kibana
'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
})
return False
logger.info('Sending MSG success.',
extra={ # the same extra data to be logged/indexed
'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
})
return True
There are two log entries, both with extra data for easy-finding in Kibana (there is a bit of redundancy in the code, so I already feel the desire to DRY it).
Then I need to add additional logging:
logger.debug("headers=%r", r.result.headers,
extra={'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient
})
And then, I need even more context in every log entry:
extra = {'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
'user': str(request.user),
'environment': env_type,
}
Combined all together, it becomes a big, unreadable blob of code. A very simple piece of logic has been spoiled by 3 log entries.
logger = logging.getLogger(__name__)
def send_message(environment: str, requester: str, recipient: str, text: str) -> bool:
""" Function send_message sends MSG to the specified recipient. """
try:
r = requests.post(settings.MSG_PROVIDER, json={'recipient': recipient, 'content': text},
... < other params > ....)
r.raise_for_status()
except requests.exceptions.RequestException as e:
logger.error('Sending MSG failed. Response text: "%s"', e,
extra={ # extra data to be logged and indexed by Kibana
'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
'user': str(request.user),
'environment': env_type,
})
logger.debug("headers=%r", r.result.headers,
extra={'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
'user': str(request.user),
'environment': env_type,
})
return False
logger.info('Sending MSG success.',
extra={ # the same extra data to be logged/indexed
'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
'user': str(request.user),
'environment': env_type,
})
return True
My solution — LogExtraCtx: #
In order to use it, just replace logging.getLogger with getLogger from logextractx.logger,
and then create local logger with local context:
from logextractx.logger import getLogger
logger = getLogger(__name__)
[...]
loclogger = logger.local(extra={'DATA_IN': 'CURRENT_CONTEXT'})
so the previous example is reduced to the following clean code:
from logextractx.logger import getLogger
logger = getLogger(__name__)
def send_message(environment: str, requester: str, recipient: str, text: str) -> bool:
""" Function send_message sends MSG to the specified recipient. """
# extra data to be logged/indexed
loclogger = logger.local(extra={'ACTION_TYPE': 'SEND_MSG',
'requester': requester,
'recipient': recipient,
'user': str(request.user),
'environment': env_type})
try:
r = requests.post(settings.MSG_PROVIDER, json={'recipient': recipient, 'content': text},
... < other params > ....)
r.raise_for_status()
except requests.exceptions.RequestException as e:
loclogger.error('Sending MSG failed. Response text: "%s"', e)
loclogger.debug("headers=%r", r.result.headers)
return False
loclogger.info('Sending MSG success.')
return True
Interesting and useful “side effect” #
Usually, it’s hard to distinguish log entries from various users. For example when you have an error in
your code and you find IndexError, you cannot be really sure to which request it belongs.
Of course, you can guess, based on chronology and many other symptoms,
but if you have many concurrent requests, then it’s hard or even impossible to associate ERROR log
with previous INFO or DEBUG.
So it’s nice to have some kind of tracking ID (request-id), that sticks to the request,
follows it and is added to every log entry until the end of request processing. It’s also worth having
session-id attached to all requests that belong to given HTTP session.
To use it in your Django project, you should use the following:
- append
logextractx.middleware.LogCtxDjangoMiddlewareto yourMIDDLEWAREin settings:
MIDDLEWARE = [
[...]
'django.contrib.sessions.middleware.SessionMiddleware',
[...]
'logextractx.middleware.LogCtxDjangoMiddleware',
]
And instead of logextractx.logger use logextractx.middleware:
from logextractx.middleware import getLogger
logger = getLogger(__name__)
[...]
Also, you need to add filter into logging
'filters': {
'RidFilter': {
'()': 'logextractx.middleware.RidFilter'
}
}
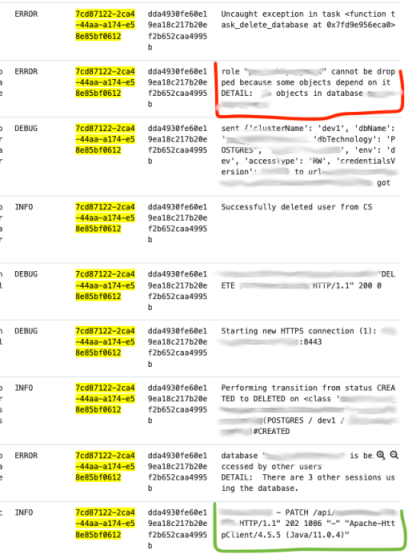
And that’s all. Now every log entry will contain request-id and session-id fields,
what looks so nice in Kibana:
Extra Formatter #
If you use plain logging format, instead of Kibana + JSON formatter, then you may be interested in using
logextractx.formatter.ExtraFormatter. Just add following in your formatter definition (DictConfig):
'formatters': {
'simple': {
'()': 'logextractx.formatter.ExtraFormatter',
'fmt': '%(levelname)s %(asctime)s %(name)s: %(message)s [%(extras)s]'
}
}
And then you will have all extra in a single log line.
Conclusion #
Logging a lot of details is good, but when it leads to breaching the DRY approach, I encourage you to use LogExtraCtx.
Also feel free to contribute — PRs are welcome.