
One task — two solutions: Apache Spark or Apache Beam?
Some time ago, our team faced the issue of moving an existing Apache Spark job from an on-premise Hadoop cluster to public cloud. While working on the transition we came across another way to process data that is Apache Beam. We were curious whether this tool had more advantages in comparison to traditional Apache Spark. We wanted to find the answer relatively quickly with minimal effort. Hence, we built two projects to process the same data using these technologies. Below you can get to know the architecture of the jobs written in Apache Spark and Apache Beam.
- Given: 4 input tables (~2.5 TB/day).
- Task: join and clean data.
- Result: 4 output tables.
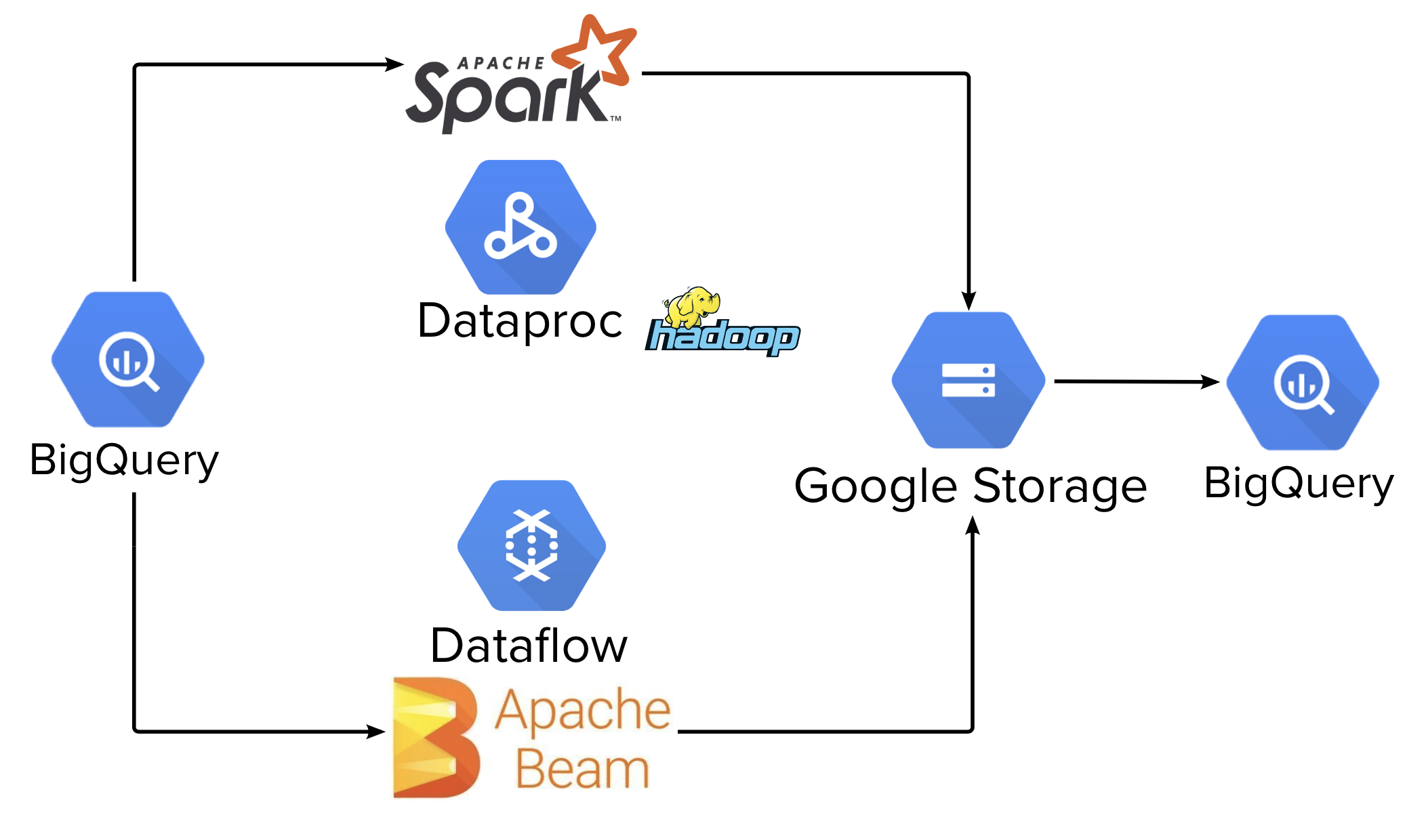
Note: Below I described our solution and used tools and technologies which do not pretend to be 100% the right approach so your results might be different.
Programming model #
The first comparison is about showing the way these technologies are built as capturing the general concept plays the first role in writing the code for data processing.
| Apache Spark | Apache Beam |
|---|---|
| Based on the in-memory MapReduce model evolved from Hadoop MapReduce. This fact forces developers to take care more of executors' memory, as mapping operations occur there. And you still need to remember about shuffling at the Join moment and how to split data to make right repartitioning (too big data chunk causes overloading on machines, too small means more shuffling over the net). How did we tune this job? The only way we knew how to do it was applying some "a-la best practices" Spark configurations, running the job with production data volume (just imagine how it reflects machine resource cost!), looking at the metrics and crossing fingers that executors will stand. Finally after n-th attempt it started working. | It pretends to be a unified processing model. What does it mean? Apache Beam is based on so-called abstract pipelines that can be run on different executors (you can even switch to the Spark execution environment). In our case we're using a DataFlow runner. This pipeline includes every stage of processing starting from data fetching, transformation, ending with the result output. With these pipelines Apache Beam hides low-level things like shuffling, repartitioning, etc. from the developer. Additionally we used BigFlow open-source framework developed internally in Allegro which is built to support Apache Beam data processing technology (simplifies building packages, configuration and deployment processes). |
Summary: Apache Beam looks more like a framework as it abstracts the complexity of processing and hides technical details, and Spark is the technology where you literally need to dive deeper.
Programming languages and build tools #
Here I do not want to spread hate and discuss which programming language is the best one for data processing, it is the matter of taste. I just would like to provide some context of our team’s background to give you better understanding of our preferences: most of us are specialised in the software development in Kotlin so we were a little bit biased against non JVM-based languages before starting this task.
| Apache Spark | Apache Beam |
|---|---|
| For the main processing part we chose Scala as it looks similar to our background in Java, although there is PySpark - version in Python. Python was used only for composing a DAG file, which is basically a description of steps to be performed by Airflow (the tool which automates running the job in the cluster). | Natively available in Java and Python, but since we took advantage of the BigFlow framework, Python was used for everything. |
| Because of Scala, sbt is used for building the package and running the tests. This can be more beneficial for Java developers who are familiar with Gradle: it uses the build.sbt configuration file, which like build.gradle declares dependencies, the Scala version to use, etc. | Setuptools (tool for building Python packages) is run by script.py build script provided by BigFlow. This framework also provides an additional mechanism for managing dependencies which is based on the standard pip-tool. Additionally running tests with BigFlow CLI is more convenient and faster compared with sbt. |
Summary: Scala is much closer to our team (mostly Java developers), especially at the beginning when we needed to get used to working with Python without static typing. Also Scala is more natural for Spark, so all upcoming features will be firstly supported for this programming language, educational resources and examples in Scala for Spark are more exhaustive.
Batch and stream data processing #
In our projects we did not implement stream data processing, since we have batch processing only, but anyway it is probable that business requirements could change so we must also consider how to do it in a better way.
| Apache Spark | Apache Beam |
|---|---|
| Two different APIs for batch/stream data processing. You need to split data yourself by grouping by the time and it is not truly real-time processing, as basically Spark divides the data stream into micro batches of X seconds called Dstreams, which is a sequence of RDDs under the hood. | Due to the unified model, processing is carried out in the same way for both batch and stream data. An additional bonus here is the useful feature for windowing (a way to split data during stream processing), watermarks and triggers (handling events that come late or out-of-order). |
Summary: although we didn’t try it ourselves, we’d bet on Apache Beam in this comparison. It looks more adapted for Streaming than Spark. Although there is a streaming extension since Spark 2.2 but libraries of streaming functions are quite limited. For us this means more efforts to apply.
Testing #
Along with the development process these projects were getting more complicated - so we realized the unit testing is not enough to make us feel safe. So below are our researches how to ensure the jobs will be able to handle big load in a production environment.
| Apache Spark | Apache Beam | |
|---|---|---|
| Unit tests (local environment without access to real infrastructure, validation of business logic) | Embedded Spark | TestPipeline |
| Integration tests (validation of proper reads/writes from/to BigQuery) | No official support for mocking BigQuery/Google Storage or embedded/test container version | |
| E2E tests (ensure job is executed, run in Cloud and has integration with GCP infrastructure) | Due to the missing implementation of testing the whole flow, we were running locally jobs to load production data, process them and store into BigQuery tables for development purposes. This way we were ensuring introduced changes did not impact performance and both return identical results. Note: recently BigFlow added a solution by setting real Dataflow/BigQuery infrastructure while running E2E tests | |
Summary: a solution is to minimize the ratio of missing test coverage and isolate classes responsible for I/O operations to external storages (Google Storage and BigQuery) as much as possible. Big issue is to provide these dependencies while running tests inside CI pipeline but this is completely another story. In both cases, it is not trivial task. So, for the sake of simplicity we were ensuring there are no performance issues and jobs are not broken by running them on a dev environment using the production data which also took us a lot of time.
Local run #
Local run in our case does not mean 100% execution on the laptop: job is triggered from the local machine, but actually it has a place on the real cluster in Google Cloud.
| Apache Spark | Apache Beam |
|---|---|
| Natively via Spark submit command. In our case we automated this by using Terraform: setting necessary infrastructure in GCP and running the job on the cluster. | BigFlow CLI |
Summary: no absolute winner here, depends on your preferences. Beside this we found Terraform to be a fine separate tool to set up a local environment for running the job and could be used for Apache Beam job as well.
Running on the GCP #
Once we are done with the local development, we are good to go to the Cloud! However, even here, not everything is so clear as we have two services to run our jobs and we described our considerations about them below.
| Apache Spark | Apache Beam |
|---|---|
| Dataproc (Hadoop under the hood which is required to run Spark). As we do not need to have it running all the time, we deployed it for each job execution, luckily we again have benefited from Terraform to do it. Also we used it to spin up the network, subnetwork, router and other things that are needed to run the Spark job within Dataproc, so I would generally recommend it as a useful tool to automate things in GCP. Dataproc has autoscaling feature, but it requires more actions: creating autoscaling policy in GCP and integrating it into the job. Moreover, to achieve good performance we needed to play a lot with Spark configuration like tuning memory on workers, choosing appropriate number of shuffle partitions, executor instances and so on. | Dataflow. Due to its serverless nature we didn’t need to set up a cluster each time we wanted to process data. The next big advantage of Dataflow is the Shuffle service, which addresses the shuffle issue on Spark executors as it moves heavy operation out of the worker virtual machine to the service backend. Besides, there is autoscaling out-of-the-box, Streaming engine for streaming pipeline support. Generally, Dataflow is supposed to be a self-managed platform, so less effort is required to configure it compared to Dataproc. |
Summary: Dataflow wins in terms of ease of the setup. However, there is one more drawback here: limitation to run on the public cloud. It was so convenient for us to profit from Dataflow services that it would be hard to find appropriate substitution for them. Furthermore, BigFlow framework positions itself as a Python framework for data processing pipelines on GCP. So if we want to migrate to another platform, this would enforce us to configure another runner so that we are able to run the job properly.
Monitoring #
In addition to the process itself, it is crucial to have an option to observe its workflow, collect metrics and have access to logs from the machines.
| Apache Spark | Apache Beam |
|---|---|
| Familiar dashboard with Yarn metrics at our disposal - Spark UI is the same that we had in the Hadoop cluster on-premise. The inconvenience was that we had to switch between different tabs in the browser. Another issue was with Spark logs UI view, as if you open it by clicking on the particular running job, you can see only the part of them. The rest can be found in GCP Logger where you need to know how to build queries to fetch them. Also Dataproc does not keep the history of metrics once the cluster is shut down. You need to spin up a separate Spark history server to collect them and then configure its visualisation in GCP Monitoring. | Logs from workers and metrics are displayed on the same UI and are available even after the job is finished. |
Summary: Dataflow beats Dataproc here and that is it. No comments are required.
Cost #
Last but not least is the pricing of used GCP resources needed to process data like setting and running a cluster, storing data and queries execution in BigQuery, etc. Here we are most likely talking not only about the money, but also about the time. As it was basically a pilot project, we calculated the cost of non-optimized jobs to see how much it is without significant tuning.
| Apache Spark | Apache Beam | |
|---|---|---|
| Cost | Approximately on the same level, slightly in favour of Apache Spark | |
| Time | 1.5h | 1h |
Summary: cost is almost the same, however we need to highlight that Spark job has much more space to optimize while Apache Beam job already contains Dataflow optimizations out-of-the-box. For example: playing more with Spark configuration, experimenting with Dataproc workers number, etc, so probably it would cost less and run faster if you know how to tune it properly.
Conclusion #
At the end we’d like to say that Spark Job could be more beneficial if you know it well. Additionally, Dataproc requires advanced skills close to the experienced DevOps engineer to organize all necessary infrastructure. But if you do not have an engineer with deep BigData experience in your team or you run out of time and you are ready to pay a little bit more for out-of-the-box features, then Apache Beam + Dataflow is your choice. Also remember even if you pay a little bit more, it means that you are saving developers’ time spent on the Spark tweaking that may bring some value.
Below you can find how we’d estimate entry level for skills that were necessary for us to develop using the two technologies.
| Apache Spark | Apache Beam | |
|---|---|---|
| Programming languages | Scala (Intermediate) | Python (Intermediate) |
| Python (Basic) | ||
| SQL (depends on your data and constraints in the executed query, generally it is recommended to load only necessary data) | ||
| Technology stack | Apache Spark (Advanced) | Apache Beam (Intermediate) |
| BigFlow (Advanced) | ||
| Google Dataproc (Intermediate) | Google DataFlow (Intermediate) | |
| Google Logging (Basic) | ||
| Terraform (Intermediate) | ||
| Google BigQuery (Basic) | ||
| Google Composer to schedule jobs in GCP (Basic) | ||
| Google Cloud Storage (Basic) | ||