

Design for failure - multiple layers of processing to protect against failures.
When designing the architecture of a system, one always needs to think about what can go wrong and what kind of failures can occur in the system. This kind of problem analysis is especially hard in distributed systems. Failure is inevitable and the best we can do is to prepare for it.
Our team deals with collecting and serving statistics for the PPC advertising platform in Allegro. We’ve decided to base our design on the Lambda Architecture, which gives us a huge benefit when it comes to fault-tolerance.
In the diagram below you can see how the Lambda Architecture maps into our platform. For simplicity, we’re focusing only on components required for collecting statistics and two types of events: clicks and emissions. An emission is the act of returning a set of ads from the system in order to display them to the user. However, since it’s a Pay-per-click system, only clicks incur fees to the advertiser.
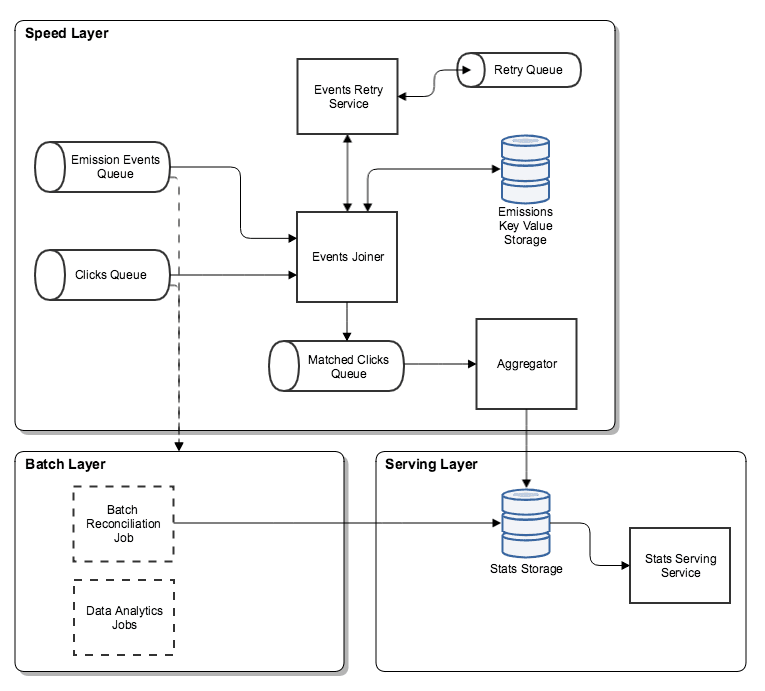
The system is divided into 3 parts:
- Speed (Online) Layer is responsible for enriching clicks (frontend events) with data from emissions (backend events) in Events Joiner service and storing aggregated statistics in a database in Aggregator service.
- Batch (Offline) Layer performs statistics reconciliation. It also allows for data analysis, as all events are dumped into a data lake.
- Serving Layer serves aggregated statistics from a database. Statistics in the database are coming from both Online and Batch Layers.
In this article, we will focus solely on the Offline Layer.
All you need to know for now is that the Aggregator is not on the system’s critical path (billing is performed earlier). We try to provide ‘near-real-time statistics’ to the users, but when anything happens in the non-critical path of the Online Layer, like message duplicates, lost events or late events, we have the option to fix the data later in the Offline Layer.
Of course, it would be possible to tackle the problems mentioned above in the Online part of the system, but in our case it would have too much impact on the system performance. That is why we have decided on a real-time best-effort and reconcile-later approach. The issue of maintaining accuracy is where our Offline Layer shines.
Offline Layer #
Let’s say you’ve designed a data processing system. It’s blazing fast and indestructible. You’ve used Kafka or SQS for communication and added circuit breakers everywhere. But what if your service shuts down mid-processing? Or your network drops packets from time to time? Maybe your system is not as resilient as you thought?
Don’t panic. Designing a data processing system that’s resilient to any kind of failure is hard. You should try to cover as many edge cases as possible, but sometimes that is not enough. Especially if processing large numbers of events and maintaining accuracy at the same time is required. There is always a chance that something will happen and your events won’t reach their destination. For example, your receiver service is down, or maybe it is the message broker that experiences difficulties. You can’t rule out network or hardware issues either. So what can you do in order not to lose any sleep over your not-so-indestructible system? That’s where the Offline Layer and batch processing come to play.
Let’s talk details. Our Speed Layer consists of microservices communicating via Hermes. Most of our Hermes topics are persisted to HDFS. This means that in our Offline Layer we are able to once again process our click and emission events and reconstruct the state of the system at any given moment. It’s a very powerful feature, not only for data analysis but also for guaranteeing data accuracy as well.
Offline data refinement and validation #
As we’ve mentioned earlier, in online processing events get lost. We’ve designed a set of batch jobs for reconciliation with the sole purpose of recomputing daily data and fixing any inaccuracies. Our stack is mostly Hadoop based, which makes Spark our technology of choice for batch processing.
We can tackle many kinds of inaccuracies:
- Lost or late clicks, due to both minor and major outages.
- Duplicated clicks.
- Fraudulent clicks.
In simple words, batch job loads all clicks and emissions from the previous day, recalculates statistics and overwrites those saved by Online Layer. In our case, this happens once a day.
Your recalculation job could look like this:
case class Click(offerId: String, emissionId: String)
//`placement` is a specific location on the webpage where an ad can be displayed
case class Emission(emissionId: String, placement: String, clickCost: BigDecimal)
class RecalculateStatisticsJob(sparkSession: SparkSession) {
def run(date: LocalDate): Unit = {
val clicks =
sparkSession
.table("clicks")
.where(s"date_partition = '$date'")
.dropDuplicates("emissionId")
.as[Click]
val emissions =
sparkSession
.table("emissions")
.where(s"date_partition = '$date'")
.dropDuplicates("emissionId")
.as[Emission]
val statistics = clicks.joinWith(emissions, clicks("emissionId") === emissions("emissionId"))
.groupBy("offerId", "placement")
.agg(
sum("clickCost").as("clicksCost"),
count("emissionId").as("clicksCount")
)
//store data in a Hive table
statistics.safeWrite(
table="statistics",
partitionColumn="date_partition",
partitionValue=date.toString)
}
}
It’s important to make the job idempotent, retryable and transactional (hence the safeWrite method). That way, even if it fails during saving the results it will leave the data in a consistent state. If anything fails or requires recomputing, you can just re-run the job.
You also have to make sure that all dependencies are ready before starting the job. It would also be nice to have monitoring for the job’s SLA. We use Airflow as our job scheduler - it handles all of that and more.
Below you will find Airflow DAG visualisation for the recalculation job.
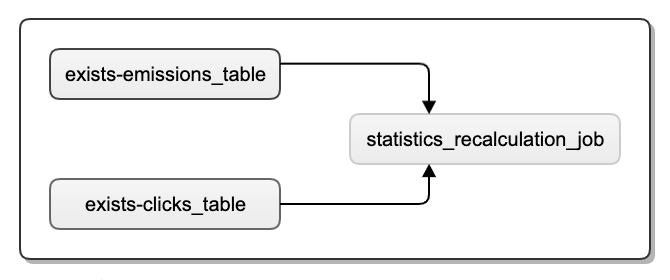
You can also include some anti-fraud validation logic in such a job (or any other kind of filtering logic for that matter) in order to recognize fraudulent clicks and to treat them appropriately, e.g. not count them in statistics and to refund their cost.
Also, in the case of any late events, you can run the job for the same day after a specified period of time to include them in the results.
Data analysis, correction and business reporting #
The Offline/Batch Layer with all the data persisted to HDFS gives you also a huge opportunity to do almost any kind of data analysis and reports your business unit can come up with. Anything that is too complex/costly to compute in real-time, would greatly increase system latency, requires an additional context, is not available in real-time or simply is a one-time data analysis can be accomplished in the Offline Layer.
Ever implemented a feature just to find out that no-one is interested in using it? Having all your historical events available can greatly reduce that risk. For every idea your Business comes up with, you can estimate how many users would use it and what impact it would have on the revenue. This allows your Business to make a decision based on data.
It’s not always about new features. Data can also be used to improve your heuristics or even find out about functionality where maintenance cost is greater than profits. For example, having historical clicks, you can pinpoint ad placements that don’t attract any potential buyers. Last but not least, storing events is an invaluable addition to A/B testing, both for proposing better candidates before the test and for in-depth analysis after.
Another advantage of the Offline Layer emerges when a bug is discovered. All the historical source data (events persisted to HDFS) is still available, so you can easily perform bug analysis. In case any data for Serving Layer, reports or other data aggregates would require recalculation, you can simply reschedule the required job on Airflow.
Metrics and alerting #
The Offline part of the system also requires metrics and alerting. Choosing good and meaningful metrics is key. We use both technical and business metrics.
Technical include:
- Task execution time.
- Task failures.
- Task SLA (e.g. results of a job that runs daily must be available before 7 A.M.).
Airflow allows configuring callbacks for task failure and SLA miss. We use them to send alerts to an on-call developer in case something is wrong. It also can send emails for lower priority issues. Of course, Airflow itself (as it is just another service) also requires monitoring and alerting if you want to be sure that it is working correctly.
Business metrics mainly refer to data trends in time (e.g. number of click events daily per placement). As we have all events persisted to HDFS, it can be accomplished by implementing a job that will gather statistics from them and check for anomalies.
Summary #
Failures in a distributed system are inevitable. Guarding against every possible failure in Online Layer is like tilting at windmills. It can lead to a very complex system, which ironically may create even more issues. Having a best-effort Online Layer and an Offline Layer for reconciliation is a relatively easy step that gives us enormous benefits. It makes our Online Layer simpler and protects us against failures. We can reconcile, analyse and monitor. The Offline Layer is one of those things that lets you sleep well at night and gives you confidence in your daily work.