
From Simple to Fast - Custom Solr Document Collapsing
At Allegro we use Solr as our main search engine. Due to the traffic to our search engine being thousands of requests per second and index size on the order of a hundred million documents we need to develop custom optimizations. In this post I will describe the story of our Solr plugin development.
Business case #
Our business owners decided to change the presentation of search results on our e-commerce website. In offer listings we were supposed to group together offers representing different variants of the same product so that they would be displayed as a single item. Variants are small modifications of the same product, for example the same model of trousers but in different size.
Beginning of development #
We decided to use Solr Collapsing Query Parser by adding a filter to the Solr query. We only needed to specify the field on which to group the results and the document sorting in order to select the most appropriate document in the group.
fq={!collapse field=group_field sort='numeric_field asc, score desc'}
Performance tests with our index size, querying load and the required SLA for response time showed that this was not a sufficient solution. The main problem with Collapser Query Parser was the load on the garbage collector. It was caused by data structures created in order to group the results during the execution of the request.
First version of custom plugin #
We decided to create our own optimized filter. To reduce memory needed to remember best collected documents so far – which was problematic with Solr collapsing filter, we decided to sort the index using identifier of each variant. Thanks to this a group of documents related to given variant were laying next to each other in an index segment. A change of the group identifier at the collection time triggers the publication of the best document.
This way we were able to use the filter to read all documents from the group, select the most suitable one and collect it. So during the request we only needed to remember one best document from the group and to compare it with the current one. We didn’t need more temporary data, that would need to be cleaned by GC, as in our first attempt with Collapsing Query Parser.
public void collect(int docId) throws IOException {
int group = groupingField.get(docId); // read group identifier
if (previousGroup == group) { // current document in the same group as a previous document
If (isBetter(docId, previousBestId)) { // current document is better than already best in current group
previousBestId = docId; // update best document in current group
}
} else { // new group
super.collect(previousBestId); // collect best document from previous group
previousGroup = group; // update current group identifier
previousBestId = docId; // update best document in current group
}
}
public void finish() throws IOException { // when whole segment is read, we collect best document from last group
super.collect(previousBestId);
}
The drawback of this solution comes from the Lucene structure itself. The filter is executed for each segment separately. Therefore, the documents from the same group may be in many segments. Documents from one group will occur in the response as many times as the number of segments in which they occur. Due to our architecture, where documents from the same group are modified and created together, there is a high probability that these documents will be in the same segment, but we do not have a 100% guarantee for it.
Second version #
More than one document from same group in the response were rare, but nevertheless we decided to develop a 100% consistent solution. The first approach was to modify the Collapsing Query Parser to reduce the data structures which are loaded during the request. The Solr plugin creates a structure that groups documents in memory, and finally presents them. In our case, however, we needed to keep only one current best document per group. It is important to emphasize that our API assumes separating queries into faceting and returning a list of results. It allows us to separate faceting queries from document list queries. Faceting queries require even less temporary data, as, for instance, there is no need to calculate the score of the document or to sort the documents in order to find the best one in each group. The performance of faceting queries proved to be sufficient. However, the performance of requests returning lists of results was not satisfactory.
Third version with priority queue #
We tried to optimize the requests’ performance by using a priority queue. Most queries return the best 100 results. The first idea was to implement grouping by attaching its implementation to Rerank Query. However, after analyzing the Lucene code, it turned out that our implementation would be based on the implementation of the TopDocsCollector subclasses. This would require the implementation of our logic in several classes, so the upgrade of our cluster to higher Solr versions could be hindered as dependent on Solr internal implementation of TopDocsCollector subclasses. We decided to filter results earlier in the filter. As a consequence, we also limited the number of collector operations returning the results.
We based our implementation on the class: FieldValueHitQueue. It is a queue sorted by the given list of fields. We have to return a list of the best N documents, one for each group.
Below is the scheme of our filter implementation.
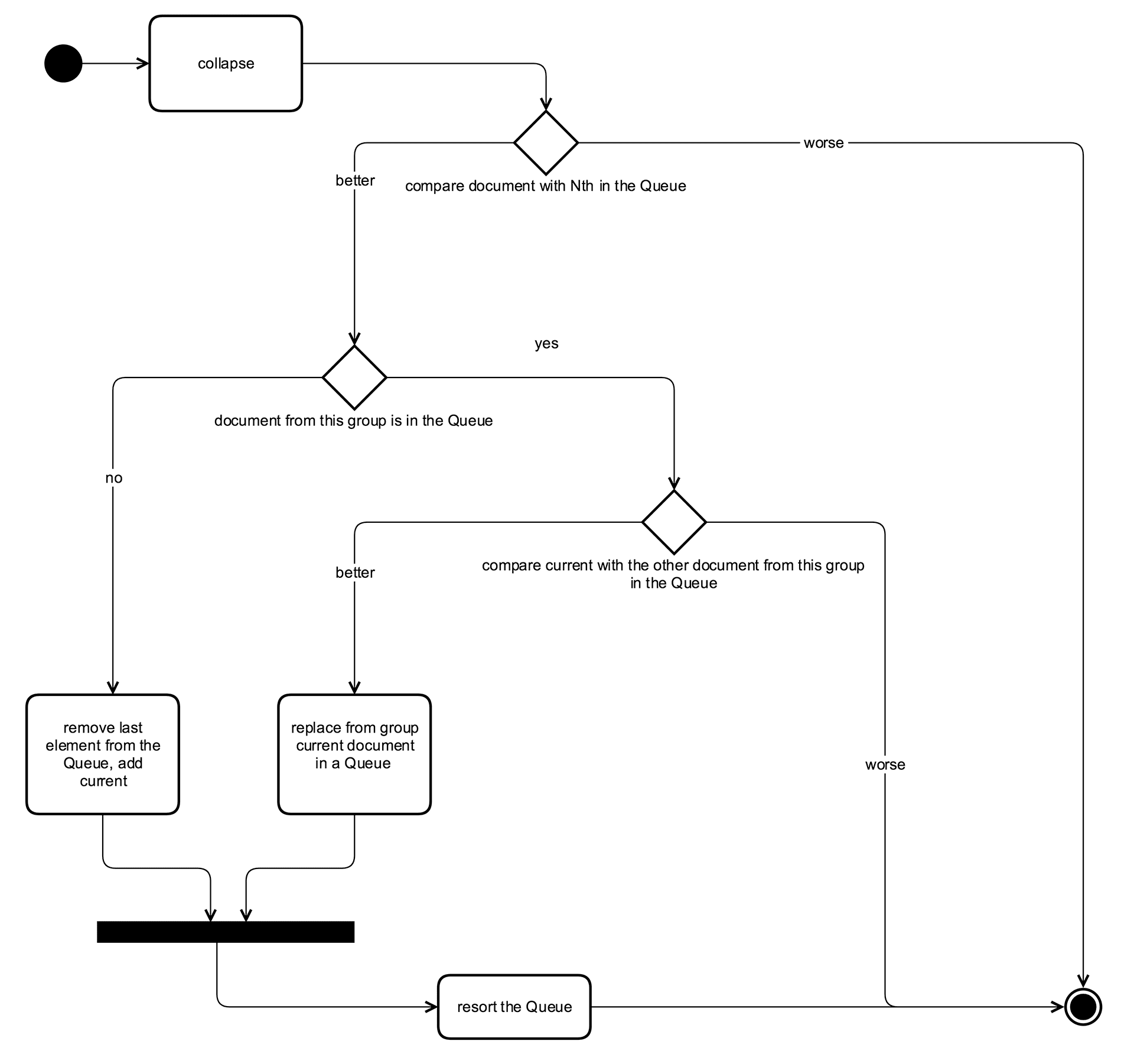
Finally, in the collector in the finish method, we return documents collected in the priority queue.
The requirement is to set our filter to be performed as the last one.
The problem with number of results #
The problem of our algorithm is the wrong number of results. The number of results in the response is the number of documents returned by our filter to the TopDocsCollector collector where this number is calculated. However, we decided to return from filter only the requested number of best documents. So, for instance, if we search for 30 best offers, we will get in response 30 documents and the total number of results will amount to 30 also. Unfortunately, this prevents us from building navigation that presents the number of result pages. In order to handle the correct number of documents available for the given criterion, we calculate the number of documents consumed by the filter and save it in a request context variable. Then at SearchComponent we change the number of returned results in the Response class.
Here is how it looks in our code:
In the finish method of our filter we put the number of document groups into the request context variable:
public void finish() throws IOException {
…
solrQueryRequest.getContext().put(“REQUEST_TOTAL_HITS”,size);
…
}
We add our own search component:
public class CollapsingSearchComponent extends SearchComponent {
@Override
public void process(ResponseBuilder rb) {
// if request contains context variable with the number of document groups
if (rb.req.getContext().containsKey(“REQUEST_TOTAL_HITS”)) {
Integer hits = (Integer) rb.req.getContext().get(“REQUEST_TOTAL_HITS”);
//response object is replaced with the number of results
rb.rsp.getValues().remove("response");
DocSlice docList = (DocSlice) response.getDocList();
DocSlice modifiedDocList = new DocSlice(docList.offset, docList.len, docList.docs, docList.scores, hits, docList.maxScore);
rb.rsp.addResponse(new BasicResultContext(modifiedDocList, response.getReturnFields(), response.getSearcher(), response.getQuery(), response.getRequest()));
//results number is also replaced in a structure used for application log
rb.rsp.getToLog().remove("hits");
rb.rsp.getToLog().add("hits", hits);
}
}
We have to instantiate this component in configuration:
<searchComponent name="collapseHits" class="org.apache.solr.search.CollapsingSearchComponent"/>
And finally in our search handler we turn it on:
<requestHandler name="/select" class="solr.SearchHandler">
<arr name="components">
<str>query</str>
<str>collapseHits</str>
</arr>
</requestHandler>
Conclusion #
Solr is a very flexible tool, it offers a lot of different ways to boost performance and customize query handling to better fit a particular use case. With the development of large solutions, we are able to modify our search engine to meet the challenges that our business brings to us. Maintaining custom changes in the search code is possible to be handled at the plugins level, which allows us to easily upgrade to newer versions of Solr.