

Presto - a small step for DevOps engineer but a big step for BigData analyst
I bet you have found this article after googling some of the issues you encounter when working with a Hadoop cluster. You probably deal with Hive queries used for exploratory data analysis that are processed way too long. Moreover, you cannot adapt Spark in your organization for every use case because of the fact that writing jobs requires quite strong programming skills. Clogged Yarn queues might be your nightmare and waiting for the launch of the container when you run even a small query drives you mad. Before we deployed Presto — a Fast SQL engine provided by Facebook — our analysts struggled with these problems on a regular basis.
Introduction #
After a technological leap forward triggered by the switch from a monolithic application to the microservice architecture, the world of analytics have changed completely. With scarce input sources supporting our solutions, a comprehensive analysis of business performance was becoming a serious a problem. We had to constantly refill the old processing platform as some data was available only via HDFS.
The idea of replacing commercial analytics solutions with a Hadoop cluster has been on our minds for some time. But analysts were skeptical about slow processing and inconvenient use. We had to be extra careful with the idea. That is why we organized two hackathons in order to evaluate the big three, i.e.
as well as Hive (on Tez, and on Spark) to set a benchmark. However, with a cluster filled with a vast set of data formats coming from various sources, to be eventually saved in HDFS, the test results were obscure. We used a sample of real-world queries our analysts work with on a daily basis, but with the benefit of hindsight, I must admit that the sample was not as representative as it should be. Despite the task complexity, we added one more aspect. We took into account an objective set of queries from a set of TPC-H benchmark queries. In the end, we were not able to make a unanimous decision, and suspended the project.
Eventually, we resumed the work in order to deliver a product under the name Fast SQL. And this time, we acted differently. The goal was clear: speeding up in-cluster analytics by an order of magnitude. Moreover, we wanted to provide users of relational databases, who were to start their adventure with Hadoop, with the most user-friendly solution possible to ensure maximum convenience during the switch.
First stage #
With a task in hand, we drafted a list of necessary and “nice to have” requirements to find a solution that would be “good enough”. We wanted the new SQL to:
- work with a secured cluster
- support data locality in HDFS
- support “short-circuit” reads
- support data formats we use:
- Json
- Avro
- Parquet
- ORC
- support complex type operations
- have good quality code
- have an active supporting community
- support carrying out analysis in a public cloud
- support high-class JDBC and ODBC drivers.
After analyzing documentation, code stored on GitHub and community support, we realized that Presto was a quite fine candidate. It would allow us to call data stored in systems such as:
- Hive
- Kafka
- Cassandra
- Accummulo.
The fact that this open-source technology is highly appreciated by innovative tech companies focused on data processing was intriguing. Presto is popular among Silicon Valley companies, but other renowned IT players such as Netflix, Uber, Twitter, Dropbox and Airbnb have also switched to Presto and contribute actively to its development.
A groundbreaking moment for the project was when Teradata announced its official support. Therefore, all the problems we had experienced during our first tests were fixed. Teradata added support for secured Hive, floating-point arithmetic as well as free high-class JDBC and ODBC drivers. As a result, many analytical tools such as Tableau work with Presto seamlessly.
Presto supports ANSI SQL standard, which is crucial for analysts experienced in working with relational databases. Support for popular standards was one of the key features we paid close attention to, as it would help lower the barrier to entry for inexperienced users and fill the gap between Hadoop and commercial solutions. According to documentation Presto features all the functions we need to work with data. A set of operators for simple and complex types may not be vast, but it is complete. Moreover, version 0.160 introduced lambda expressions for more demanding users.
We wanted a solution that could be migrated into a public cloud, and Presto suited us. This technology is heavily used in private data centers (Facebook) and cloud (Netflix). This year, Amazon has added a new service — Athena — to its analytics stack in AWS. As Athena is based on a Presto engine, it somewhat confirmed our findings.
Besides, we could not ignore the fact that Presto Software Programming Interface, which is simple and clear, can be used for creating plugins for custom tools or services, but mostly for creating UDFs adjusted to our needs. Moreover, the Presto source code, whose quality helps mitigate the technical debt, deserves A+.
After the preliminary examination, we decided to move to the next stage, i.e. proof of concept.
Presto vs Hive #
Before we move on to discuss next stages of the project and tests we carried out, let us explain why Presto is faster than Hive. Cluster’s infrastructure involves one coordinator and many workers that are ready to process queries right after being launched, so you do not waste time for creating sessions and spawning Yarn containers.
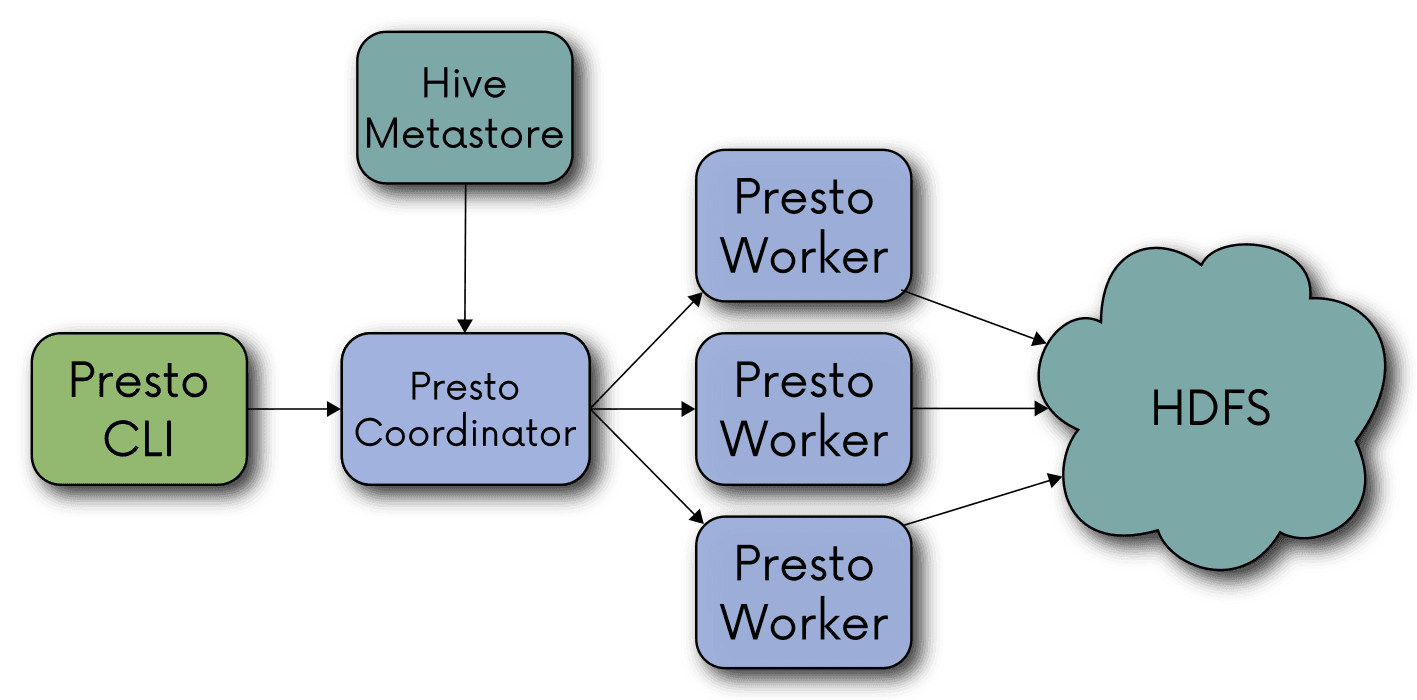
Data is stored in memory as an optimized internal data structure and streamed between the processes when moving to consecutive stages of execution plans. Therefore, intermediary data is never saved on a drive when computing the query results.
Libraries for memory management, communication between distributed services and generating bytecode are true examples of state-of-the-art coding. All these features contribute to reducing the time of query execution by an order of magnitude. However, to have a highly efficient cluster you need to invest in separate Presto infrastructure.
PoC #
Eventually, it was high time to test Presto under real-world conditions. As we were sure of our choice, we added suitable modules to Allegro Hadoop Manager (developed in Puppet) to deploy and conveniently manage Hadoop clusters and data processing tools. We deployed Presto on the target infrastructure based on bare metal because we considered any tests carried out in other environments (cloud?) to be unreliable. It took one engineer a few days to deploy and configure the platform.
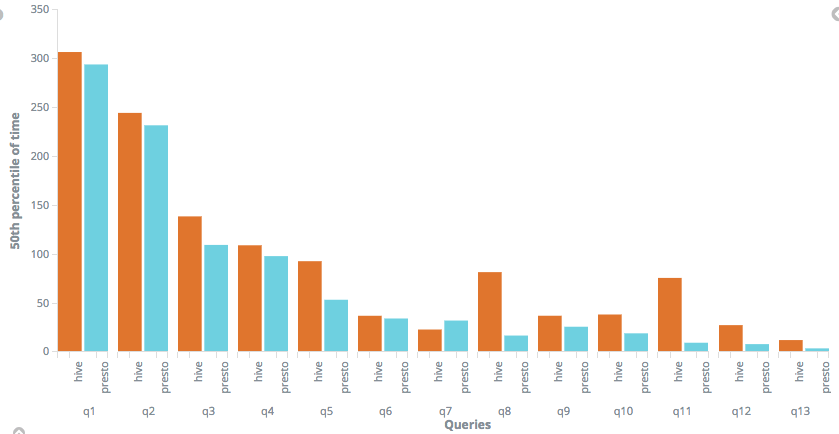
The results of first tests carried out with real queries concerning real-world data were significantly better compared to Hive ver. 1.2. Presto turned out to be at least 4 times faster than a control sample.
The only error we had to deal with was Filesystem closed returned by workers and a coordinator. It was caused by HDFS
NameNodes flooded with queries from Presto threads. When the NameNode was receiving queries from different threads, but
coming from the same virtual machine bearing identical Kerberos identity and the same timestamp, it responded correctly
only to the first one, treating the rest of them as a replay attack, thus sending Request is a Replay according to
applicable standards. Therefore, if a Kerberos authentication protocol is used in communication between a distributed
system and a service then tokens should be applied or communication should be repeated, if necessary. We solved that
problem by releasing a fix processing the request.
Tests #
We also compared Presto to new Hive ver. 2.1 using the same infrastructure. Facebook’s solution won the easiest test to carry out, i.e. execution time. In overall Presto performed test queries 3x faster.
Ecosystem #
You can work with Presto in many ways. Owing to HTTP protocol used in communication between client and coordinator, you simply need to retrieve an executable jar file to submit queries via a computer’s command line interface. All you need is Java — forget about any additional libraries or software.
We chose Alation – a collaborative data platform for analysts – as a starting point for work with data because it provides access to data from all processing engines we support in production. It is worth emphasizing that analyses can be shared between employees.
With Teradata drivers we can extend our ecosystem by tools that use Fast SQL. It means you can create cubes and reports in Tableau and users used to SQL Developer have DataGrip at their disposal. Nonetheless, remember that drivers are compatible with a version released by Teradata, which somewhat binds you to this particular branch. And there is no guarantee it will be opened in the future, but so far all Teradata changes were contributed to opensource.
Tests with analysts #
A testing session with analysts, the first users of the new solution, was crucial. After meeting all our technical and performance requirements, we wanted to check Presto under real-life conditions and decided to somewhat leave the deployment decision in the hands of future users.
For this reason, we had organized workshops to present basic analytical tasks and the feedback we received was astonishing. It turned out that Hadoop can be fast. Moreover, by supporting ANSI SQL it was possible to work with the platform immediately. Users also appreciated simple query syntax. Consecutive versions of a query based on a sample of data were executed in no time, saving time and pleasing our analysts. Convenient API and clear documentation were the icing on the SQL cake.
It was almost too good to be true, but luckily (sic!), we faced some new challenges. For example problems that occurred when working with data saved as AVRO files. AVRO is a file type replacing JSON in internal communication between our services. We had to fix a definition of tables and partitions in Hive because schemas saved in HDFS were not read properly. We also had to switch to the HTTP protocol. In order to make Presto support backward compatibility of schemas, we replaced a particular partition version with the latest one. All these changes concerned only the description of structures in Metastore and did not require any modification of Presto and Hive code.
Security measures #
Presto offers two mechanisms for user authentication: Kerberos and LDAP. For the sake of users, we selected LDAP, which does not require a separate initiation of a Kerberos ticket. Access to data and coordinator panel is granted after providing a password, and this mode should be applied when setting communication with Presto coordinator via HTTPS protocol. However, some analytical tools, e.g. Alation do not support this particular authentication method. However, it is not a real problem as Alation has a mechanism for user authentication, and when the software is used as a trusted proxy, it can send task to an unsecured endpoint. Our configuration supports both communication modes for a coordinator, and communication without authentication is available only in the case of tools that confirm user identity.
The second security element involves access authorization to resources. A lot has changed in this regard, in particular when Hive data is concerned. Presto offers 4 authorization modes:
- legacy
- read-only
- file
- sql-standard.
At present, we use the sql-standard mode, which is secure from the data access control perspective and provides the greatest work flexibility. The SQL mode involves modification of rights per user, which is a time-consuming operation for platform engineers if you take into account the scale of operations in a data collection and massive migration of analysts to Presto. Access to resources in a Hadoop cluster has been granted based on Active Directory groups in order to ensure process security, auditability and automation. And we want to extend it over our new Fast SQL platform. The issue is being verified, but Presto does not support Hive’s policy based on access rights to resources stored in HDFS (Storage Based). Presto does not impersonate users when communicating with Hive Metastore, as impersonating takes place only when communicating with HDFS.
Beta version #
After completing the testing phase, we faced the last stage of deployment into production. Some processing and analyzing operations were moved to a Presto cluster that was assigned the beta status. In order to get the solution ready, we decided to run one large project involving different queries.
Under continuous work conditions we noticed GC issues occurring on a regular basis. During a full GC, a worker was dropping out of a cluster due to lost communication with a coordinator. As a result, partially executed queries were immediately closed with an error. However, these were the assumptions made when designing the system. With Fast SQL one can execute queries so fast that in the event of any problems with a worker, an analyst may repeat the query and get the results after a moment. The work will be done, but the failing executioner will be omitted. Nonetheless, in the case of Presto, Full GC in production environment should be treated as a failure. Class histogram of a JVM process showed too many objects responsible for communication with secured HDFS. The leak had been diagnosed and fixed in a new version, so our part involved adjusting the patch.
In April, Teradata released new Presto 167T. Teradata’s release cycle is different from the baseline, with new versions released less frequently, usually once a quarter. A single branch release includes several versions. Nevertheless, such frequency suits us just fine, and we can always try to deploy changes earlier, if necessary.
New Presto version from Teradata supports anticipated lambda expressions and features an improved and more complex Parquet plugin. Unfortunately, the support for maps and tables implemented in that plugin somewhat affected reading of nested structures. Nevertheless, we decided to stick to the newest version after installing a minor fix we created to block New Parquet Reader when reading Tables and Maps. Moreover, we reported the problem on github.
Summary #
The project was successfully delivered. Presto was deployed into production and we were able to revolutionize processing in Hadoop. Although it is quick, response time is not all that matters. We wanted to have a complex view of technology and for that reason we focused more on workshops helping us find answers to real-world challenges in analytics. There were some bumps on the way, but we managed to deal with them, which also may give you some idea about the quality of Presto.
When you think about it, the project Presto — Fast SQL is far more than a merely technological change. We have three key aspects here:
- Business: we can solve real (simple or complex) business problems. Moreover, we can provide reports on business performance and trends to follow.
- Ask Fast — Fail Fast: With Presto we can execute queries fast and prototype them quickly by using limits in subqueries. Forget about waiting for several minutes before creating a new version of a query.
- Flexibility: we have an adjustable tool that is easy to launch and configure.