
Hitting the Wall
Running Mesosphere Marathon is like running… a marathon. When you are preparing for a long distance run, you’ll often hear about Hitting the wall. This effect is described mostly in running and cycling but affects all endurance sports. It happens when your body does not have enough glycogen to produce power and this results in a sudden “power loss” so you can’t run anymore. At Allegro we have experienced a similar thing with Mesosphere Marathon. This is our story on using Marathon in a growing microservice ecosystem, from tens of tasks and a couple applications, to thousands of tasks and over a hundred applications. If there is no mention of Marathon version, it is 1.3.10 and below; we need some time to test and deploy the latest 1.4 release. If you are interested in how our ecosystem is built, take a look at below MesosCon presentation.
</div></div>
History #
A couple of years ago we decided to completely change the architecture of our system. We used to have a monolithic application written in PHP with a bunch of maintenance scripts around it. Changing this system was not easy, and what matters the most, not fast enough for our business to grow. We decided to switch to the microservice based architecture. This switch required changing our infrastructure and the way we operate and maintain our applications. We used to have one application and now we wanted to move to many small applications that could be developed, deployed, and scaled separately. In the beginning, we tried to launch applications in dedicated VMs, but it was neither efficient in terms of resource allocation nor fast or agile, so we searched for a different solution to this problem. When we began our journey to microservices and containers, there were not so many solutions on the market as there are today. Most of them were not matured and not battle-proven. We evaluated a couple of them and finally, we decided to use Mesos and Marathon as our main framework. Below is the story of our scaling issues with Marathon as our main (and so far only) framework on top of Apache Mesos. Below image is a snapshot of a traffic visualization for our services. It is generated with vizceral.
Problems #
JVM #
Marathon is written in Scala and runs on the Java Virtual Machine. Take a look at GC and heap usage metrics and if you see Marathon spends a lot of time in GC or you can’t see a saw shape on your heap utilization graph, check your GC and heap settings. There are many talks and tutorials on tuning a JVM.
Zookeeper #
Marathon uses Zookeeper as its primary data storage. Zookeeper is a key-value store focused more on data consistency than availability. One of the disadvantages of Zookeeper is that it doesn’t work well with huge objects. If stored objects are getting bigger, writes take more time. By default, a stored entry must fit in 1 MB. Unfortunately Marathon data layout does not fit well with this constraint. Marathon saves information about deployment statuses as old application group, deployment metadata and updated group MARATHON-1836. That means if you deploy a new application, deployment will use twice as much space as your application’s group state. In small installations it’s not a problem (until some of them leak MARATHON-1724), but when you have more and more applications, over time you will notice your Zookeeper write times take longer and at some point you will end up with the following error:
422 - Failed to deploy app [/really/important/fix] to [prod].
Caused by: (http status: 422 from https://production).
RESPONSE: [{
"message":"Object is not valid",
"details":[{
"path":"/",
"errors":[
"The way we persist data in ZooKeeper would exceed the maximum ZK node
size (1024000 bytes). You can adjust this value via --zk_max_node_size,
but make sure this value is compatible with your ZooKeeper ensemble!
See: http://zookeeper.apache.org/doc/r3.3.1/zookeeperAdmin.html#Unsafe+Options"
]
}]
}]
This error will be thrown by Marathon when you want to deploy a critical fix (Murphy’s law works perfectly). This was a huge problem until Marathon 0.13, but now Zookeeper compression is turned on by default. It generally works well, but still, it’s not unlimited, especially if your app definitions do not compress well. So if they don’t you will hit a wall. Marathon 1.4.0 brings a new persistent storage layout so it might save you.
Another issue with Zookeeper, like with any other high consistency storage, is the network delay between nodes. You really want to put them close to each other and to create a backup cluster in another zone/region to switch quickly in case of an outage. Having cross-DC Zookeeper clusters causes long write times and often leader reelection.
Zookeeper works best if you minimize the number of objects it stores. Changing
zk_max_version (deprecated) from default 25 to 5 or less will save some space.
Be careful with this if you often scale your applications because you can hit
MARATHON-4338
and lose your health check information.
Metrics #
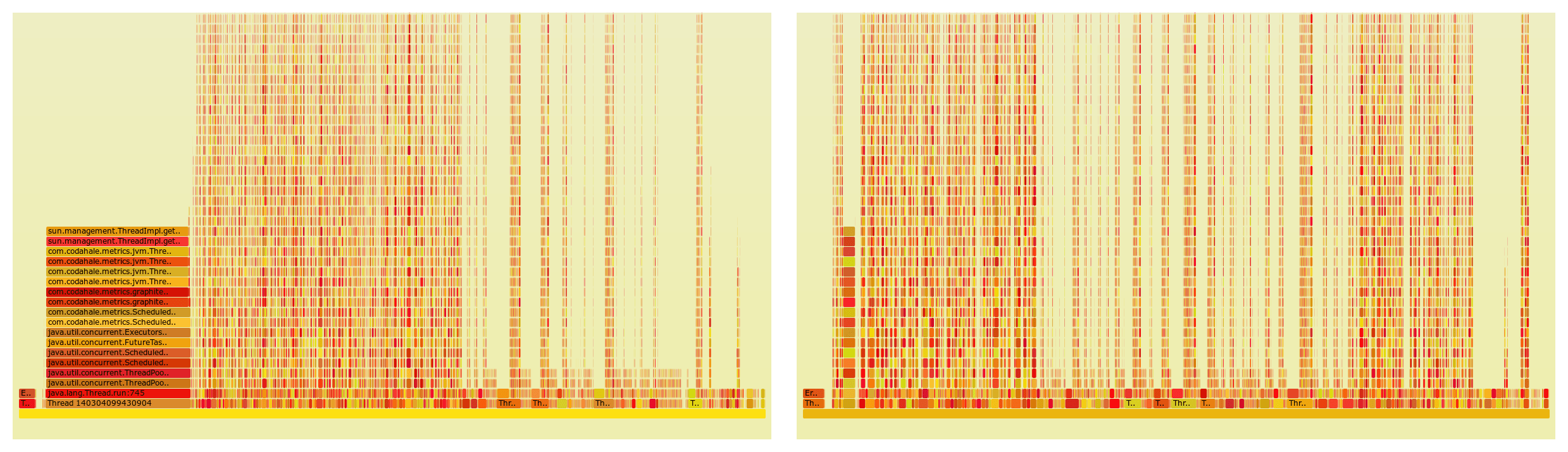
Marathon 0.13 was one of the biggest releases of Marathon. It brought many improvements and bugfixes. It also brought metrics collection and sending them to Graphite and Datadog. This is nice. Unfortunately, soon we started having problems with CPU usage on our Marathon cluster. We profiled it with Honest Profiler and it turned out that Marathon was spending 20% of its time on metrics collection. By default metrics are collected every 10s so we changed this to 55s and reduced time spent on collection to less than 2%. Below you can see a flame graph presenting how much CPU time every method takes. You can compare how much CPU time gathering metrics takes with interval set to 10 seconds (left) and 55 seconds (right).
Threads #
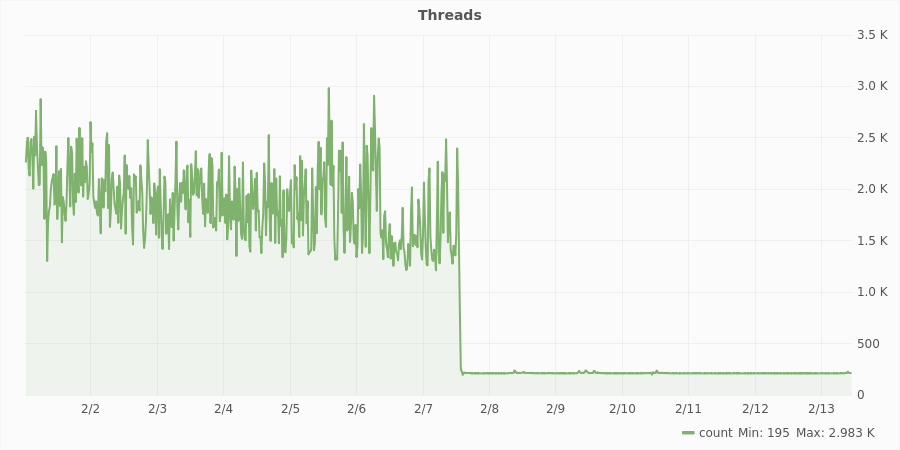
Marathon uses Akka as an actor framework. Its configuration suggests that there should be 64 threads in akka pool and 100 threads in IO pool. This configuration seems valid. When our cluster grew and we were having more and more applications, we noticed that thread number also increased. With 2k tasks we had up to 4k threads. This is quite a lot and we lost precious CPU time on task switching. After weeks of hard work we managed to reduce this number to 200 threads and our changes were merged and released in 1.3.7. Still, it’s more than the configured value but we will be able to handle this. Below you can see a diagram presenting how number of threads decreased after updating Marathon.
Another optimization we introduced was to increase
akka.default-dispatcher.throughput to 20. According to
the docs
this setting will make actors operate on batches of messages.
Throughput defines the maximum number of messages to be processed per actor before the thread jumps to the next actor. Set to 1 for as fair as possible.
This is a double-edged sword. Too low a value will totally decrease performance because of actor switching and CPU cache flushes resulting from context switches. On the other hand, too high a value could cause actor starvation and timeouts. We increased it 4 times and saw a small improvement.
Healthchecks #
Marathon has had HTTP health checks from the beginning, before they were introduced in Mesos. Each of our tasks have a configured HTTP healthcheck. Because Marathon makes requests from a single machine — the currently leading master — it’s quite expensive, especially when you need to make thousands of HTTP requests. To reduce the load we increased the Marathon health check interval. Fortunately in the meantime Mesos incorporated HTTP health checks and they were added to Marathon 1.4, so soon we can switch and make checks locally on agents. There is a great post on Mesos Native HTTP healtchecks. You can read there that Marathon checks work up to 2k tasks while Mesos scales well. If you want to switch to Marathon 1.4 and use Mesos healthchecks keep in mind it’s a new mechanism and there are issues with it: MESOS-6786, MESOS-6790.
Events #
Marathon allows two ways of event subscription. HTTP callbacks (deprecated from 1.4) when events are pushed to a subscriber with HTTP POST and Server-sent events (SSE), and when the subscriber makes a connection and retrieves the events. Since callbacks look easier from a developer perspective we created services using this method. It’s just a regular web application accepting POSTs. First problem is the size of events. They could be big (our biggest event is nearly 10 MB — see MARATHON-4510). For example deployment events contain the whole deployment object — this means the whole Marathon application state before and after deployment, and steps that will be performed by Marathon in order to complete it. Another drawback with callbacks is that events can’t be filtered, so filtering needs to be done on subscriber side. This is a waste of CPU and network resources, because events need to be serialized to JSON and then parsed back, only to be eventually dropped. Currently Marathon spends most of it’s time on parsing events. We added filtering by event type to SSE and moved to this subscription.
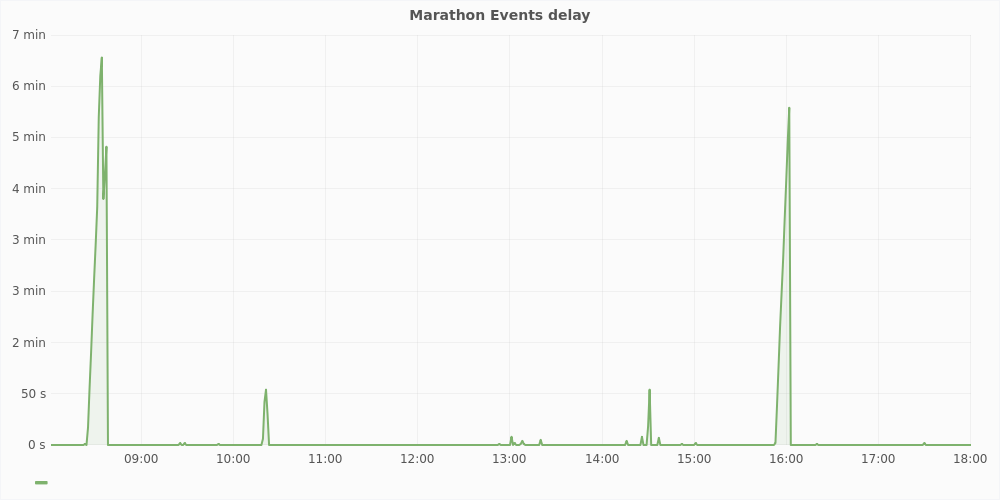
Another problem with subscriptions is that they are an asynchronous way of communication. We are currently using them in marathon-consul but we see it’s not the best way of registering services in discovery service. Due to JSON parsing and sending, subscriptions performance is sensitive to CPU and network load. When many deployments are triggered at the same time we experienced lagging events for a couple of minutes. The following graph presents typical events delay for one of our cluster in a typical workday. Below you can compare unfiltered callbacks, and filtered SSE events delay. Data was gathered with marathon-consul.
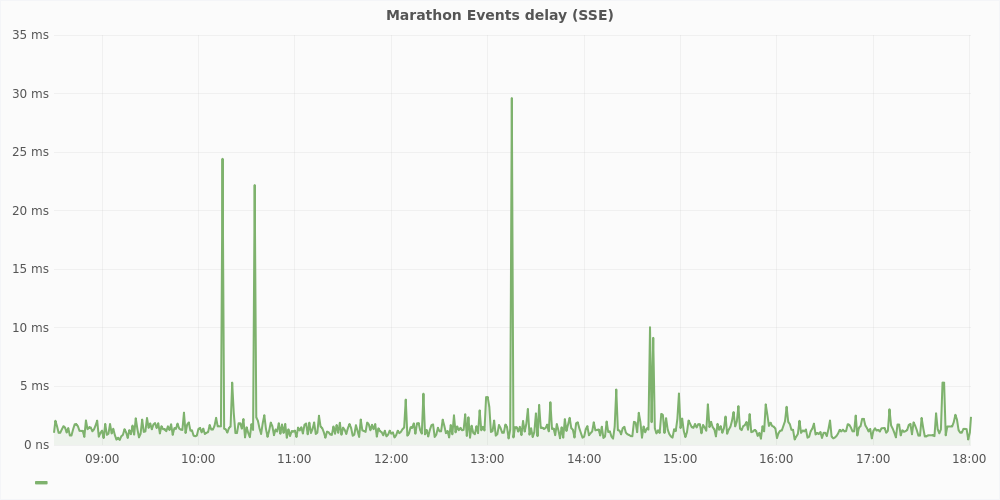
Our solution to this problem is to create a custom executor that will register an application in our systems just like Aurora does. This will give us necessary blocking features on actions that are critical and could not be done asynchronously. Unfortunately there is an issue with custom executor support and it looks like nobody is using it MARATHON-4210.
Deployments #
At a company with over 600 developers located in one timezone, multiple deployments occur at the same time. This is a problem for Marathon since it must update the state in Zookeeper and this blocking operation sometimes times out. If you can try to group deployments and send them in one batch, then Marathon will work. Instead of sending many request (one for each application), send one requests with an array of applications to be deployed. This solution is not perfect, for example you can’t stop or rollback the deployment of a single application in a batch so we didn’t introduce such a feature yet. By the way, stopping an application is dangerous MARATHON-2340.
Autentication and Authorization #
Marathon has a plugin module that allows adding custom fine-grained authentication
and authorization. Do not use it. We tried and we failed. Its API changes with every
release. But what is more, the API only allows checking permissions for
a single application in one request.
This means that if you have thousands of applications and you want
to query /v2/apps, Marathon will call your plugin thousands of times, and then
render a response with only the applications you can see.
Instead of using this plugin, create a facade that will authenticate requests and remove from them any data users should not see.
Sharding #
If you feel like your installation could grow and want to be prepared, think about sharding. You can run many Marathon instances on a single Mesos cluster. What is more, you can run Marathon on Marathon (MoM). Here is a test for it and here you can find a DCOS package for Marathon. With this setup you can mitigate most of the issues described above, by reducing load on a single Marathon instance.
Community and support #
Community around Marathon is pretty small, especially when compared with Kubernetes or Docker. Container orchestration is still emerging and not many people are involved in this project. If you have a problem you can submit an issue, ask on the mailing list or stack overflow. But do not expect a fast answer.
Speaking as the lead of marathon, I’ll say this:
We have to support the company first which has a more integrated solution that actually has to make money at the end of the day. We are also a pretty damn small team with a huge backlog to deliver, so it sucks that we had to abandon the UI outside of DCOS. We hope that the components of the DCOS UI for marathon can become the native UI for marathon, but again, it’s a balance of priorities.
Marathon by itself has a lot more coming in the future, some will be restricted to DCOS, but not everything, it’s a balancing act. Given our history of changing course publicaly (I wasn’t involved in these decisions), I’m waiting to share our plans for 1.5 until I’m confident we’re committing to them.
Just a quick two cents.
Marathon team is small and needs to work on Mesosphere’s paying clients. This means less important features or community requests will not have much attention.
Could you please update the docs so we (paying enterprise customers) don’t have to discover it the hard way?
— Comment on MARATHON-1643 (formerly dcos/metronome-#100), January 25, 2017
Being a business client does not necessarily mean you will have proper support or documentation.
If you want to monitor what is happening with Marathon codebase prepare for frequent changes. Over the years the Marathon team tried different code review and management tools. They started with vanilla Github, then moved to Waffle.io to finally settled on JIRA. For code review they used Github, reviewable.io and now they prefer phabricator. Their CI system also changed from Travis thru TeamCity to Jenkins.
Overall, it is easier to monitor what happens with Marathon than it used to be when Mesosphere worked in a private repo and had a silence period with no communication to the community. Still, there is no roadmap but you can figure out what will happen based on Mesos and Marathon issues and pull requests.
Summary #
To sum up, Marathon is a nice Mesos framework for installations of a few thousand applications. If you have more than a few thousand applications and more then 10k tasks you will hit the wall.
How to avoid the wall: #
- Monitor — enable metrics but remember to configure them.
- Update to 1.3.10 or later.
- Minimize Zookeeper communication latency and object size.
- Tune JVM — add more heap and CPUs :).
- Do not use the event bus — if you really need to, use filtered SSE, and accept it is asynchronous and events are delivered at most once.
- If you need task life cycle events, use a custom executor.
- Prefer batch deployments to many individual ones.
- Shard your marathon.
If this still does not help try Aurora. It has fewer features and slower development but is battle tested on huge capacity at Twitter and more stable than Marathon. If you need a bigger community, support from more than one company and faster development try Kubernetes.
Whatever way you choose remember:
The ecosystem around containerization is still emerging and is in a rapid state of flux.