
Deep learning for frame detection in product images
At Allegro we are faced with a technical challenge: how to recognize whether a given image (a product thumbnail) shows just a product itself. One of the things that we would like to detect is when the product is surrounded by a frame. In this post we would like to present our approach for detecting a frame in the image.
Example #
This is an image that shows just a product:

While this is the same product surrounded by a frame:

The frame can be of any color/texture and it can be present only on one side of the image:

This problem looks straightforward, at least for humans. It gets a bit more tricky if we consider products that are of rectangular shapes and they obviously shouldn’t be detected as frame:

Baseline solution #
As a baseline we used an existing system built in-house. It uses a Canny edge detector and a ruleset for deciding whether particular number of edges imply frame existence.
Deep learning #
Why did we decide to try deep learning and in particular convolutional neural networks (CNN) to solve this problem?
CNNs are currently used in all state-of-the-art solutions to problems of image classification/segmentation etc. If you are interested in this topic we will briefly explain the structure of the CNN and provide description of building blocks applied to construct it, namely:
- convolutional and pooling layers, responsible for feature extraction.
- fully connected layers (along with dropout layer), which perform classification tasks.
How does it work? #
Convolution #
Let’s illustrate what we mean by convolution in our context on a one dimensional signal:
import numpy as np
signal = [1,4,5,10,5,3,4,15,4,3,2]
convolution_filter = [ -1, 1, -1]
np.convolve(signal,convolution_filter,mode='valid')
>> [-2, -9, 0, -8, -6, -14, 7, -14, -3]
So it is sliding the convolution filter over a signal and calculating a dot product between part of the signal and convolution filter. The same happens for an image which we treat here as a 3D signal (width, height, color).
Here you can find a detailed explanation of convolution in CNN.
Neuron #
Artificial neuron is a processing unit that has n inputs, each associated with a weight. When doing forward-pass the data comes through the input, each input is multiplied by its weight, then weighted inputs are summed. Sum is passed to an activation function that makes the neuron non-linear. In CNN the best results are usually achieved when using ReLu activation as ReLu is fast for back-propagation and do not have the vanishing gradient problem.
Neural network #
A neural network is a combination of many neurons that work together and depending on their structure can mimic arbitrary functions. For binary classification last layer consists of a single neuron followed by a sigmoid activation function to make the output interpreted in terms of probability for each class.
Combining everything in one concept… Deep Convoluted Neural Networks #
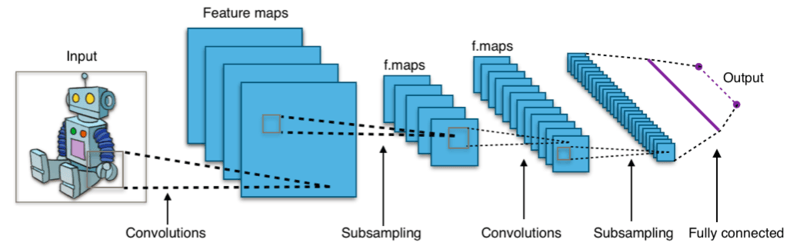
A convolutional neural network is a neural network with multiple layers where first layers use convolution to process input together with an operation called pooling which decrease image resolution when it goes through the network. Top layers closely resemble a traditional neural network with fully-connected layers.
Example of a CNN:
Our approach and experiments #
Dataset #
Initially we used a Google Chrome plugin to download images tagged by humans but that process didn’t scale well.
So we decided to use a semi-automated way of gathering a test set which was:
- classify a sample of images using existing frame detector which is known to have ~92% accuracy.
- manually go through each class moving erroneous 8% of images to a proper class.
This way we gathered around 5K images in a few hours.
Network architectures #
There are no good guidelines on what architecture to use for a specific problem. Most researchers trust their intuition — which is not something one can learn easily.
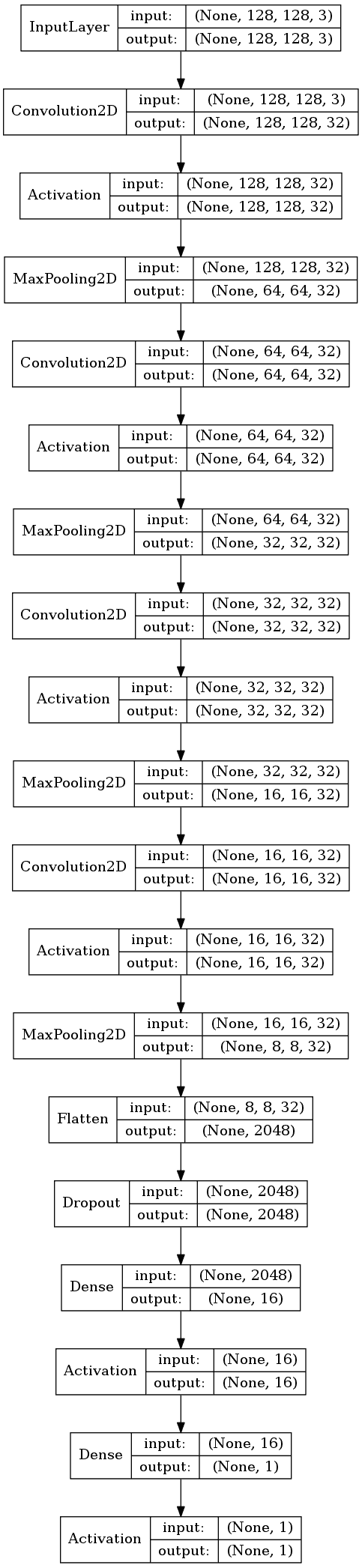
We decided to start from a not-so-deep network, and evolve — trying out different aspects of architectures to find a good one. One limitation was the size of our dataset which was far smaller than some public datasets used in really deep networks. Our current best network takes a 128x128 pixels RGB image as an input and consists of 4 convolutional layers (each of 32 depth and 3x3 kernel size) together with maxpooling layers and on top a fully connected layer and a binary classification layer.
Final architecture #
We trained using stochastic gradient descent optimizer, we experimented with network configuration (number of layers, depth of the layers, global pooling layers) various pooling operations, removing/minimizing fully-connected layer. We wanted to make the model good enough but not become very big because of two reasons:
- Runtime performance depends on the size of the network.
- Such networks already have 50K-100K of parameters that need to be trained on only 5K images, so there is a chance of overfitting (this is a situation when a model learns particular dataset properties and not a general problem).
To tackle overfitting we used a validation set and train data augmentation, e.g. flipping images vertically or horizontally when training to make the dataset artificially bigger without affecting image distinguishable features.
Evaluation & Results #
As a final metric we chose accuracy (fraction of images correctly classified) since our dataset was well-balanced (similar number of images in each class).
Here is a sample from our trained models:
| name | train_accuracy | val_accuracy |
|---|---|---|
| 128_32-32-32-32_conv3_fc16_sgd_lr_0_01_decay_0_00005 | 0.985 | 0.964 |
| 128_16-16-16-16_conv3_fc16_sgd_lr_0_01_decay_0_00005 | 0.987 | 0.955 |
| 128_16-16-16-16_conv7_fc16_sgd_lr_0_03_decay_0_00005 | 0.998 | 0.952 |
Our baseline algorithm had 92.3% accuracy.
Here is a comparison of a ROC Curve of both baseline and our new model:
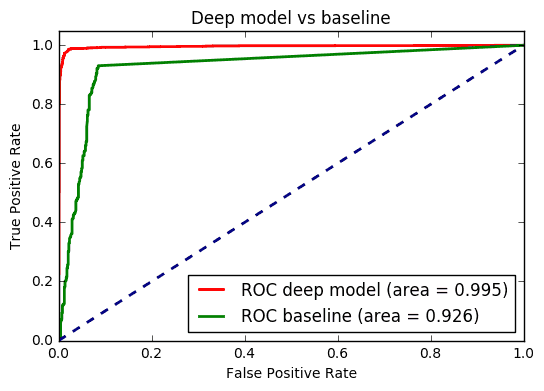
Best deep model had 96.4% accuracy on validation set. We were able to go even to 99.8 % accuracy on training set which proves that the model was complex enough for our data.
We didn’t take a more strict approach like cross-validation due to long training times. It took 5 hours to train a 4-layered network for 200 epochs.
Tools #
We used Keras which is a really awesome DSL for building Deep Learning models on top of TensorFlow. Jupyter notebook served as an environment for experimentation and data-driven-development. We wrapped everything in a Docker container for reproducibility and production deployment. We first used commodity hardware (workstations and cloud machines) and then switched to GPU machines to train the models.
Production deployment #
Prediction for a single image takes ~15ms which is fine for our case.
We considered using TensorFlow Serving which is a tool for publishing TensorFlow models but we decided that this was a bit too heavy and complex for our simple use case.
We decided to export the model to a file and read it on a server having Keras and Tensorflow installed.
Conclusions #
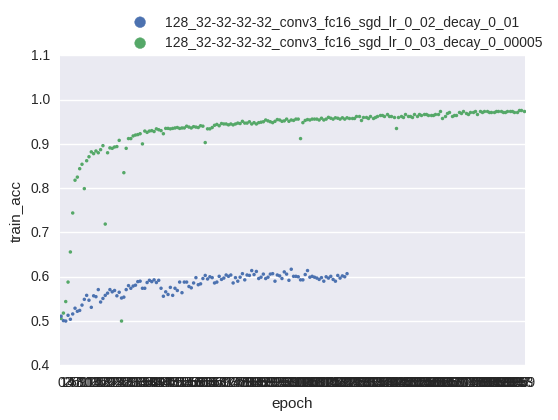
- Observe your experiments as they do not always tend to converge. Below you can see a chart of accuracy vs number of epochs of two experiments. The blue one didn’t go very well comparing to the green one. The reason for that is probably too high learning rate decay.
- Data gathering is hard — errors sneak in all the time, so we were fixing the dataset through all of the experiment timespan.
- Baseline solution made it possible to remove the frame altogether. This solution cannot do that so far, although given a pixel-annotation dataset — deep learning can solve the problem of object segmentation as well.
More on deep learning: #
- Deep Learning is nowadays used to solve many great challenges not only in image processing but also in sound processing or
Natural Language Processing.
- DeepMask can segment each independent object in a picture.
- NeuralTalkv2 creates textual descriptions of what is seen on an image.
-
Google deep dream is able to create new art-pieces of a given style.

(CC BY-SA 4.0 https://commons.wikimedia.org/wiki/File:DeepDreamingProcess.jpg)
Resources #
If you are interested in this topic I recommend these resources as a starting point:
- Deep Learning Course on Udacity — a solid no-fluff course with short videos explaining many aspects of deep learning.
- List of awesome deep vision resources
- The 9 Deep Learning Papers You Need To Know About
- Deep Learning Book