
Spark and Kafka integration patterns
Today we would like to share our experience with Apache Spark, and how to deal with one of the most annoying aspects of the framework. This article assumes basic knowledge of Apache Spark. If you feel uncomfortable with the basics of Spark, we recommend you to participate in an excellent online course prepared by the creators of Spark.
The devil is in the detail #
Big Data developers familiar with MapReduce programming model are usually impressed with elegant, expressive and concise Spark API which complies with functional programming style. Unfortunately, as soon as they start to develop more complex applications, they run into subtle issues related to the distributed nature of Spark’s internals. Spark API is only a thin abstraction and, as we all know, abstractions in computer science tend to leak.
The problem we would like to discuss here is the problem of object serialization and lifecycle management
in Spark applications.
Sooner or later you may observe strange java.io.NotSerializableException exceptions in your application stack trace.
This happens because some part of your application code is evaluated on the Spark driver, other part
on the Spark executors.
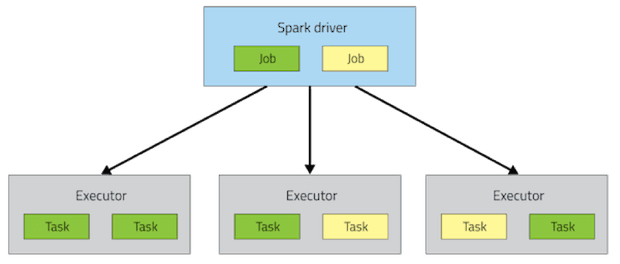
In the example below, Spark creates two jobs on the driver and delegates work to executors on a cluster of remote
nodes.
The number of jobs depends on your application business logic and the number of tasks depends on data partitioning.
When you gain some experience with Spark, it should be easy to look at the code, and tell where it will be eventually executed. Look at the code snippet below.
dstream.foreachRDD { rdd =>
val where1 = "on the driver"
rdd.foreach { record =>
val where2 = "on different executors"
}
}
}
The outer loop against rdd is executed locally on the driver.
RDD (Resilient Distributed Dataset) is a structure
where data is transparently distributed to cluster nodes.
The only place you can access rdd is the driver.
But the inner loop will be evaluated in a distributed manner.
RDD will be partitioned and inner loop iterates over subset of rdd elements on every Spark executor.
Spark uses Java (or Kryo) serialization to send application objects from
the driver to the executors.
At first you will try to add scala.Serializable or java.io.Serializable marker interface to all of your application
classes to avoid weird exceptions.
But this blind approach has at least two disadvantages:
-
There might be a performance penalty when complex object graph is serialized and sent to a dozen of remote cluster nodes. It might be mitigated by using Spark broadcast variables, though.
-
Not everything is serializable, e.g: TCP socket cannot be serialized and sent between nodes.
Naive attempt to integrate Spark Streaming and Kafka producer #
After this introduction we are ready to discuss the problem we had to solve in our application. The application is a long running Spark Streaming job deployed on YARN cluster. The job receives unstructured data from Apache Kafka, validates data, converts it into Apache Avro binary format and publishes it back to another Apache Kafka topic.
Our very first attempt was very similar to the code presented below. Can you see the problem?
dstream.foreachRDD { rdd =>
val producer = createKafkaProducer()
rdd.foreach { message =>
producer.send(message)
}
producer.close()
}
The producer is created (and disposed of) once on the driver but the message is sent to an executor. The producer keeps open sockets to the Kafka brokers so it cannot be serialized and sent over the network.
The producer initialization and disposal code can be moved to the inner loop as presented below.
dstream.foreachRDD { rdd =>
rdd.foreach { message =>
val producer = createKafkaProducer()
producer.send(message)
producer.close()
}
}
Kafka producer is created and closed on an executor and does not need to be serialized. But it does not scale at all, the producer is created and closed for every single message. Establishing a connection to the cluster takes time. It is a much more time consuming operation than opening plain socket connection, as Kafka producer needs to discover leaders for all partitions. Kafka Producer itself is a “heavy” object, so you can also expect high CPU utilization by the JVM garbage collector.
The previous example could be improved by using foreachPartition loop.
The partition of records is always processed by a Spark task on a single executor using single JVM.
You can safely share a thread-safe Kafka producer instance.
But in our scale (20k messages / second, 64 partitions, 2 seconds batch) it did not scale as well.
Kafka producer was created and closed 64 times every 2 seconds and sent only 625 messages on average.
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val producer = createKafkaProducer()
partitionOfRecords.foreach { message =>
connection.send(message)
}
producer.close()
}
}
If you are interested in more details about above optimizations, look at the design patterns published in the official Spark Streaming documentation. Perhaps the patterns were prepared for regular database connection pools, when single database connection cannot be shared between clients concurrently. But a Kafka producer is a thread-safe object, so it can be easily shared by multiple Spark tasks within the same JVM. Moreover, Kafka producer is asynchronous and buffers data heavily before sending. How to return a Kafka producer to the pool, if it is still processing data?
Problem solved #
Finally we ended up with a solution based on Scala lazy evaluation (you can do it in Java as well).
The application code is very similar to our first naive attempt when Kafka producer is managed fully on the driver.
To ensure that kafkaSink object is sent only once we use the Spark broadcast mechanism.
val kafkaSink = sparkContext.broadcast(KafkaSink(conf))
dstream.foreachRDD { rdd =>
rdd.foreach { message =>
kafkaSink.value.send(message)
}
}
KafkaSink class is a smart wrapper for a Kafka producer.
Instead of sending the producer itself, we send only a “recipe” how to create it in an executor.
The class is serializable because Kafka producer is initialized just before first use on an executor.
Constructor of KafkaSink class takes a function which returns Kafka producer lazily when invoked.
Once the Kafka producer is created, it is assigned to producer variable to avoid initialization on every send() call.
class KafkaSink(createProducer: () => KafkaProducer[String, String]) extends Serializable {
lazy val producer = createProducer()
def send(topic: String, value: String): Unit = producer.send(new ProducerRecord(topic, value))
}
object KafkaSink {
def apply(config: Map[String, Object]): KafkaSink = {
val f = () => {
new KafkaProducer[String, String](config)
}
new KafkaSink(f)
}
}
Before production deployment, KafkaSink needs to be improved a little.
We have to close the Kafka producer before an executor JVM is closed.
Without it, all messages buffered internally by Kafka producer would be lost.
object KafkaSink {
def apply(config: Map[String, Object]): KafkaSink = {
val f = () => {
val producer = new KafkaProducer[String, String](config)
sys.addShutdownHook {
producer.close()
}
producer
}
new KafkaSink(f)
}
}
The function f is evaluated on an executor so we can register shutdown hook there to close the Kafka producer.
The shutdown hook will be executed before the executor JVM is closed, and Kafka producer will flush all buffered
messages.
Summary #
We hope that this post will be helpful for others looking for a better way to integrate Spark Streaming and Apache Kafka. While this article refers to Kafka, the approach could be easily adapted to other cases where a limited number of instances of “heavy”, non-serializable objects should be created.