
Search Engines at Allegro — Part I — introduction
There’s no denying that the most important way to reach an offer on Allegro is a search bar. How it works from the user’s point of view everybody knows. You input a search phrase, select some filters when needed, click “search” and you get some results, usually quite fast. What looks like a simple and straightforward process on the surface, inside actually engages really complicated algorithms. In this first post of the series we will try to make you a little bit familiar with the tools we use here at Allegro to make search happen. In an upcoming post, we will describe how to use them, focusing mainly on the analysis process.
But let’s start from the beginning - with a software library called Lucene…
Lucene — one library to rule them all #
Before we start, let’s draw a mental picture here — our need is to be able to look for some phrases in a document set. First idea could be simple — why not use something similar to LIKE from SQL. First attempt on a larger document set shows just how bad an idea it is — LIKE is extremaly slow and also it doesn’t help with finding different forms of a single word. What is immediately clear is that some kind of processing must be done in order to to provide faster and more functional ways of searching. That is exactly the motivation for creating Lucene — not the first, but certainly the most popular open source search engine library today.
Lucene was created in 1999 by Doug Cutting — the same guy who went on to create Hadoop later. Lucene is written in Java. Over the years many ports emerged, but, as it usually happens to unofficial ports their development ceased and some point. Basic goal of Lucene is to transform the incoming data (both incoming documents and queries) into a form which allows fast and functional searching, and, of course, handling the search itself. The output searchable data we call index and the process of transformation is called an analysis.
Index #
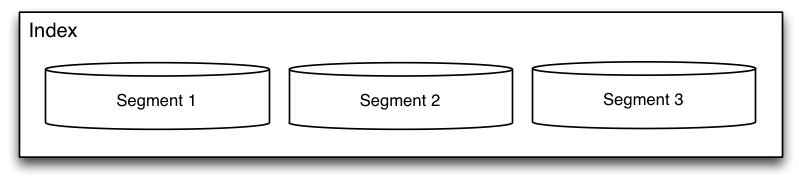
Main problem here is: how do we provide fast matching of the query to the document set? Lucene’s anwser to this problem is the index. Lucene’s index isn’t a classical b-tree index where keys point to some data, but a flat inverted index where the data can be used to find matching identifiers. This index isn’t uniform — it’s divided into segments on which the search is performed separately, to be merged later. The process which is being used both during the creation of the index and quering is called an analysis.
Analysis #
Long story short, analysis is a process of turning text into data that can be indexed. But what does it mean? The original text is divided into words, whereas words are converted into more useful forms – the letter case is unified, diacritical marks such as those used in Polish are replaced with their non-diacritical counterparts, and sometimes words are saved in their base form. The analysis can be modified, as the process consists of many simpler operations. The next article will describe some of them we use. The analysis is crucial when indexing documents and queries. The process does not have to be identical. Output consists of terms – usually single words if we deal with text – and the numbers of occurrences and the positions in the original text (unless the field configuration includes omitNorms=true).

Usually, individual documents are not indexed on a disk right away. They are stored within an in-memory index and saved to disk once in a while as a new segment. Nevertheless, owing to policies that can be configured, it is possible to join the segments later. We will delve deeper into the process in our next blog post related to search engines.
Query #
Each query is analysed the same way as documents, although you can apply different analysis settings to each field you query. Next, the terms created after the query analysis are used to locate identical terms in each segment.
Search engines #
Lucene is a library. As a result, it is easy to add a searcher to any application, but it requires manual processing of various input formats, index optimisation or search distribution. Luckily, you do not have to deal with all those issues, as special Lucene-based services were created. We are going to focus on two of them that are used at Allegro.
Apache Solr — older and more mature solution #
Solr was created in 2004 by Yonick Seeley, who is still one of Solr’s committers. In 2010, Solr and Lucene projects were merged and now they are released together. Currently, the service is based on collections that reflect the Lucene index, but they also offer replication and sharding, not available in Lucene. The engine is so popular that the community of its users organise Lucene/Solr Revolution conference once a year. Moreover, the service provides a scheme that can be defined (and created dynamically by following some rules), which allows users to create Lucene documents with properly defined index and query analyzers. It supports replication and sharding. It also offers scaling, but Cloud Computing scaling was added quite late to a rather mature service, forcing some modifications to the logic. At Allegro, we use Solr to store our largest and oldest indexes.
Elasticsearch — young, but active #
It is a successor of the Compass library. Both products are created by Shay Banon and support Lucene library. Elasticsearch was created in 2010 to ensure the most flexible search (in fact, the name tells it all). Elasticsearch is incredibly easy to use, but at the same time it offers the same configuration options as Solr. Moreover, its creator used transparent rest API and added Java libraries that translate this API into a binary protocol. Another important feature are plugins that can extend the functionality of libraries. Nevertheless, the most important current feature of the Elasticsearch ecosystem is its BigData application. The data structure is based on indexes, but unlike Lucene, Elasticsearch divides documents into different types to search them. Additionaly, the search engine supports sharding and replication – by default, each new index is divided into 5 shards and each has one replica. Currently, we use Elasticsearch not only for tasks related to searching. We also use the service for analysing data, geographic search and processing application logs with the superb ELK package.
Deep down the rabbit hole #
We explained some basic terms and presented two main products related to Lucene. In an upcoming article in the series, we will go deeper into the process of how Lucene works. Stay tuned!