Online MongoDB migration
MongoDB is the most popular database used at Allegro. We have hundreds of MongoDB databases running on our on—premise servers. In 2022 we decided that we need to migrate all our MongoDB databases from existing shared clusters to new MongoDB clusters hosted on Kubernetes pods with separated resources. To perform the migration of all databases we needed a tool for transfering all the data and keeping consistency between old and new databases. That’s how mongo-migration-stream project was born.
Why do we needed to migrate MongoDB databases at all?
At Allegro we are managing tens of MongoDB clusters, with hundreds of MongoDB databases running on them. This kind of approach, where one MongoDB cluster runs multiple MongoDB databases, allowed us to utilize resources more effectively, while at the same time easing maintenance of clusters.
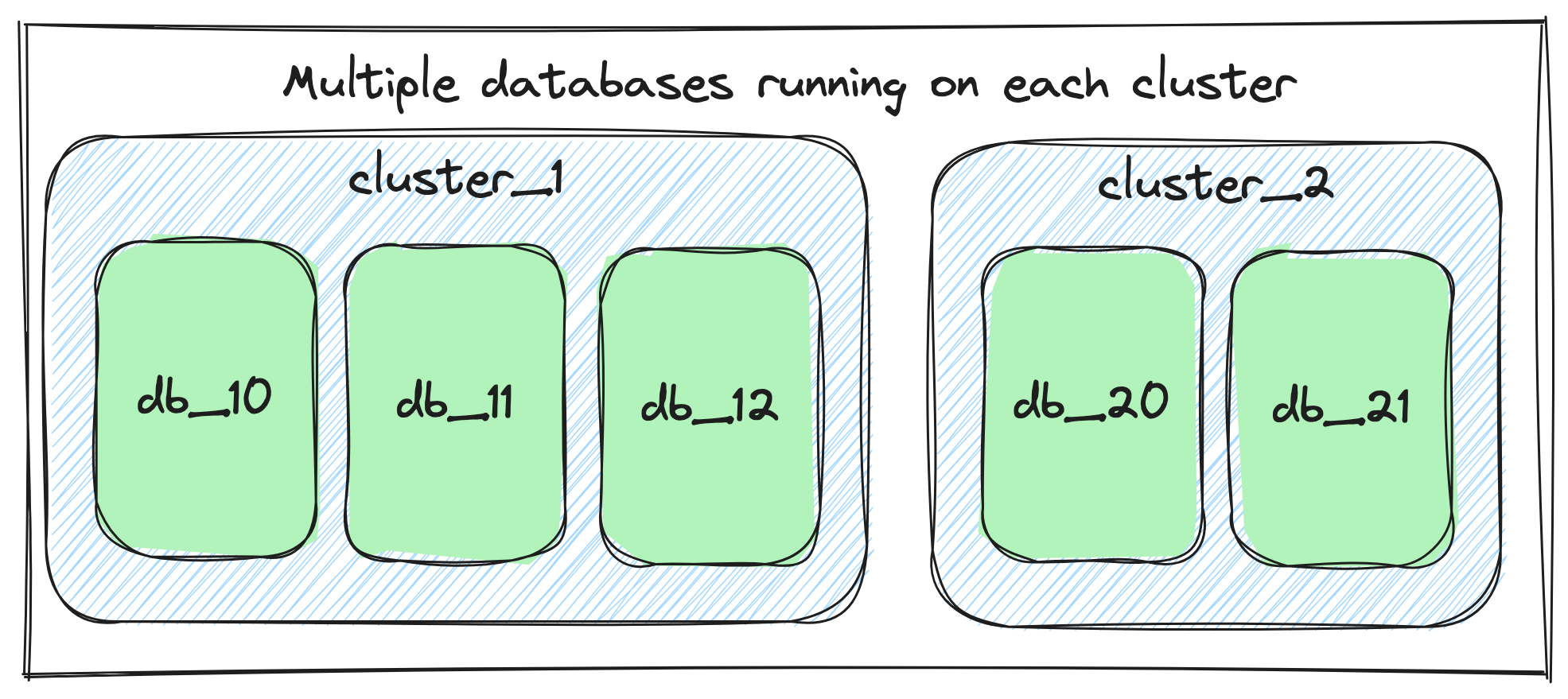
We’ve been living with this approach for years, but over time, more and more databases were created on shared clusters, increasing the frequency of the noisy neighbour problem.
Noisy neighbour problem
Generally speaking, a noisy neighbour situation appears while multiple applications run on shared infrastructure, and one of those applications starts to consume so many resources (like CPU, RAM or Storage), that it causes starvation of other applications.
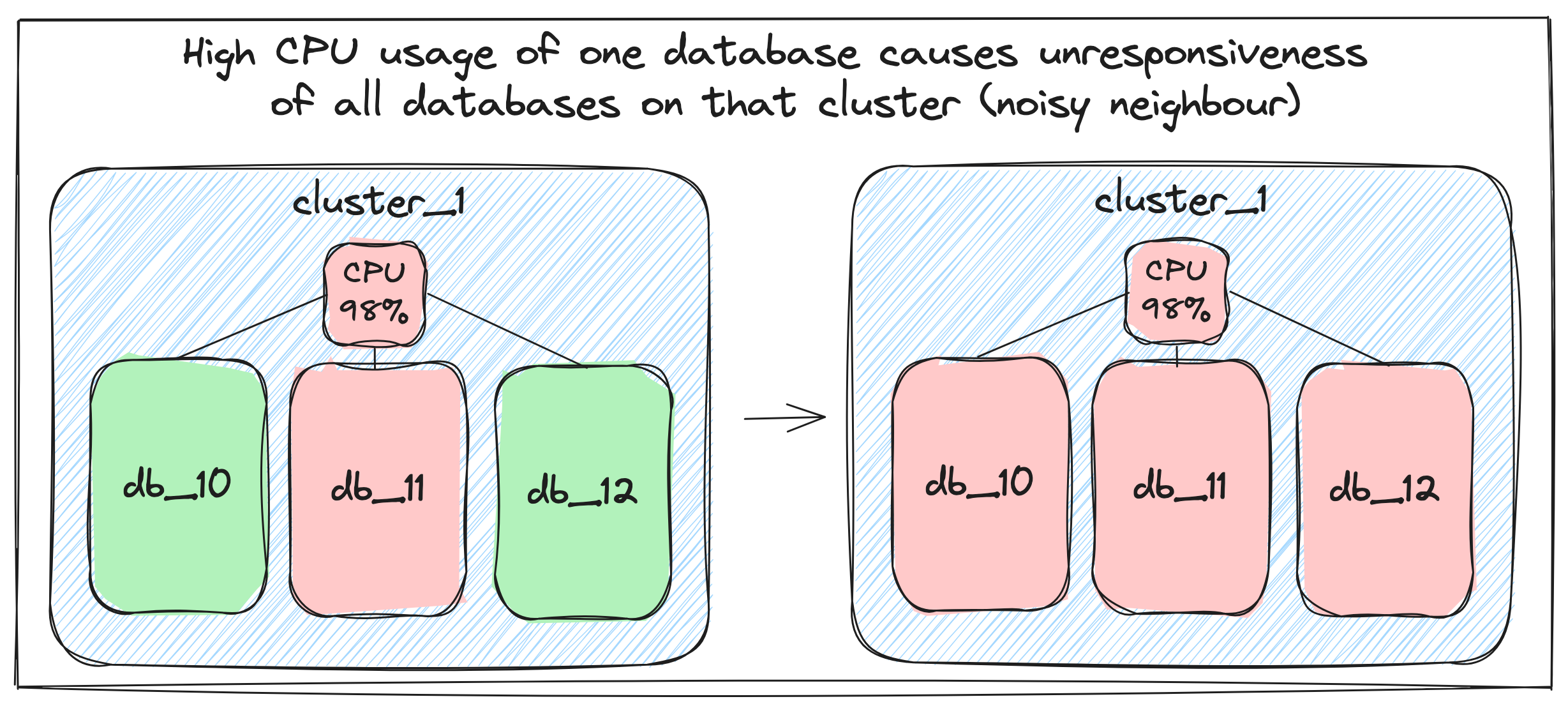
At Allegro this problem started to be visible because over the years we’ve created more and more new MongoDB databases which were hosted on a fixed number of clusters.
The most common cause of the noisy neighbour problem in the Allegro infrastructure was long time high CPU usage caused by one of MongoDB databases on a given cluster. On various occasions it occurred that a non-optimal query performed on a large collection was consuming too much CPU, negatively affecting all the other databases on that cluster, making them slower or completely unresponsive.
MongoDB on Kubernetes as a solution to the noisy neighbour problem
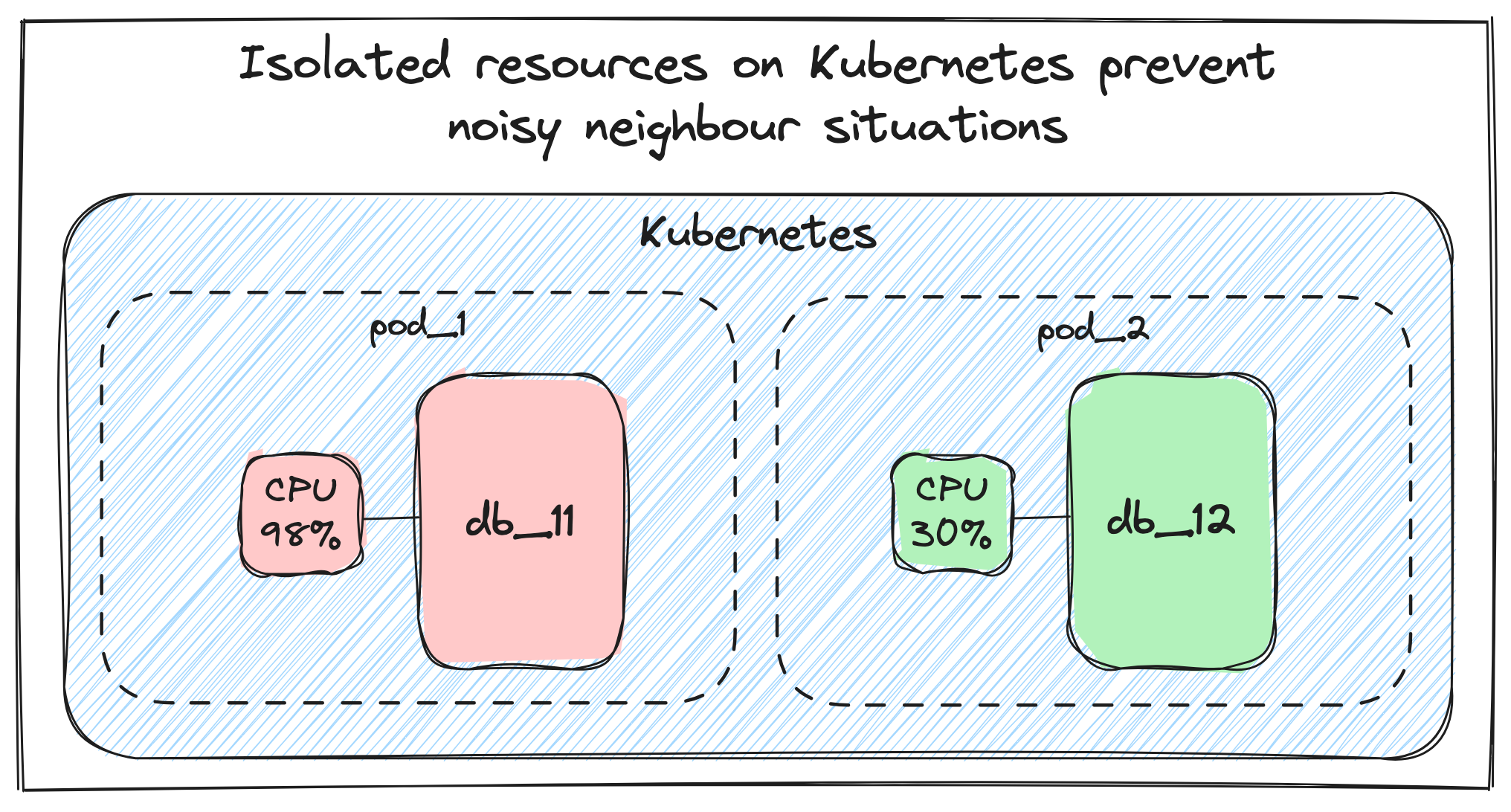
To solve the noisy neighbour problem a separate team implemented a solution allowing Allegro engineers to create independent MongoDB clusters on Kubernetes. From now on, each MongoDB cluster is formed of multiple replicas and an arbiter spread among datacenters, serving only a single MongoDB database. Running each database on a separate cluster with isolated resources managed by Kubernetes was our solution to the noisy neighbour problem.
At this point we knew what we needed to do to solve our problems — we had to migrate all MongoDB databases from old shared clusters to new independent clusters on Kubernetes. Now came the time to answer the question: How should we do it?
Available options
Firstly, we prepared a list of requirements which a tool for migrating databases (referred to as migrator) had to meet in order to perform successful migrations.
Requirements
- Migrator must be able to migrate databases from older MongoDB versions to newer ones,
- Migrator must be able to migrate
ReplicaSetsand sharded clusters, - Migrator must copy indexes from source database to destination database,
- Migrator must be able to handle more than 10k write operations per second,
- Migration must be performed without any downtime,
- Migration cannot affect database clients,
- Database owners (software engineers) need to be able to perform migrations on their own.
Existing solutions
Having defined a list of requirements, we checked what tools were available on the market at the time.
py-mongo-sync
According to documentation py-mongo-sync is:
“Oplog—based data sync tool that synchronizes data from a replica set to another deployment, e.g.: standalone, replica set, and sharded cluster.”
As you can see, py-mongo-sync is not a tool that would suit our needs from end to end. py-mongo-sync focuses on the synchronization of the data stored on the source database after starting the tool. It doesn’t copy already existing data from the source to the destination database. What’s more, at the time py-mongo-sync supported MongoDB versions between 2.4 to 3.4, which were older than those used at Allegro.
MongoDB Cluster-to-Cluster Sync
On July 22, 2022 MongoDB released mongosync v1.0 — a tool for migrating and synchronizing data between MongoDB clusters. As described in the mongosync documentation:
“The mongosync binary is the primary process used in Cluster—to—Cluster Sync. mongosync migrates data from one cluster to another and can keep the clusters in continuous sync.”
This description sounded like a perfect fit for us! Unfortunately, after initial excitement (and hours spent on reading mongosync documentation) we realized we couldn’t use mongosync as it was able to perform migration and synchronization process only if source database and destination database were both in the exact same version. It meant that there was no option to migrate databases from older MongoDB versions to the newest one, which was a no-go for us.
When we realised that there wasn’t a tool which met all our requirements, we made a tough decision to implement our own online MongoDB migration tool named mongo-migration-stream.
mongo-migration-stream
mongo-migration-stream is an open source tool from Allegro, that performs online migrations of MongoDB databases.
It’s a Kotlin application utilising
mongodump and mongorestore MongoDB Command Line Database Tools
along with Mongo Change Streams mechanism.
In this section I will explain how mongo-migration-stream works under the hood, by covering its functionalities from a high—level overview and
providing details about its low—level implementation.
mongo-migration-stream terminology
- Source database - MongoDB database which is a data source for migration,
- Destination database - MongoDB database which is a target for the data from source database,
- Transfer - a process of dumping data from source database, and restoring it on destination database,
- Synchronization - a process of keeping eventual consistency between source database and destination database,
- Migration - an end-to-end migration process combining both transfer and synchronization processes,
- Migrator - a tool for performing migrations.
Building blocks
As I’ve mentioned at the beginning of this section, mongo-migration-stream utilises mongodump, mongorestore, Mongo Change Streams
and a custom Kotlin application to perform migrations.
mongodumpis used to dump source database in form of a binary file,mongorestoreis used to restore previously created dump on destination database,- Mongo Change Streams are used to keep eventual consistency between source database and destination database,
- Kotlin application orchestrates, manages, and monitors all above processes.
mongodump and mongorestore are responsible for the transfer part of migration,
while Mongo Change Streams play the main role in the synchronization process.
Bird’s eye view
To implement a migrator, we needed a robust procedure for migrations which ensures that no data is lost during a migration. We have formulated a procedure consisting of six consecutive steps:
- Start listening for Mongo Change Events on source database and save them in the queue,
- Dump all the data from source database using
mongodump, - Restore all the data on destination database using
mongorestore, - Copy indexes definitions from source database and start creating them on destination database,
- Start to push all the events stored in the queue (changes on source database) to the destination database,
- Wait for the queue to empty to establish eventual consistency.
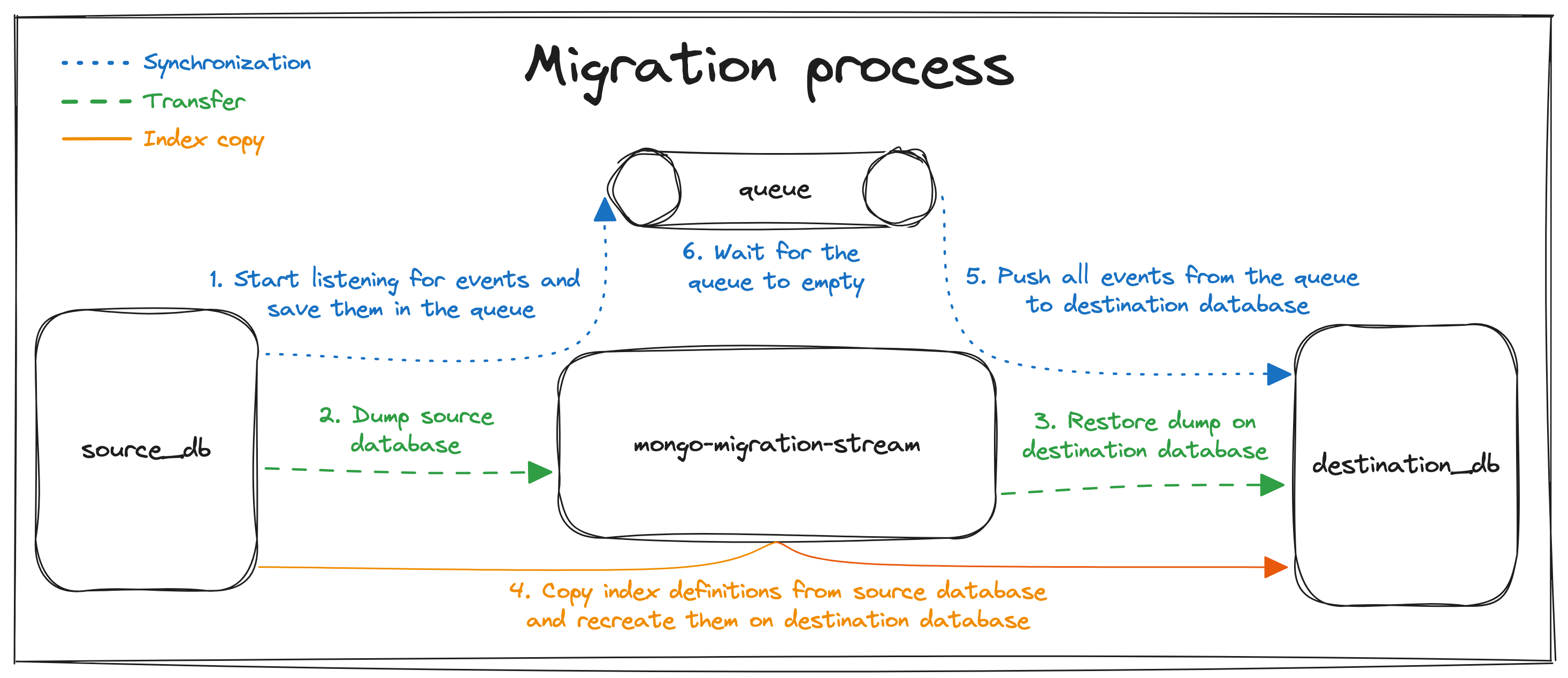
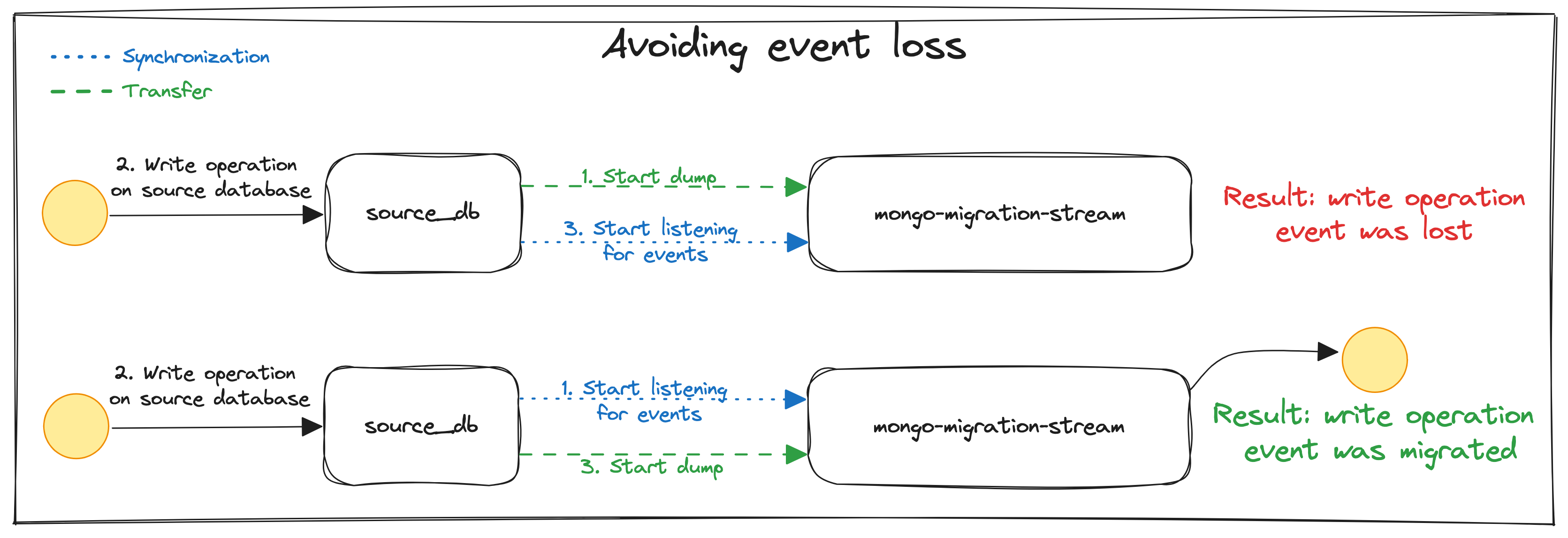
Our migration procedure works flawlessly because processing Mongo Change Events in a sequence guarantees migration idempotency. Without this characteristic, we would have to change the order of steps 1 and 2 in the procedure, creating a possibility of losing data during migration.
To explain this problem in more detail, let’s assume that the source database deals with a continuous high volume of writes. If we had started the migration by performing dump in the first place and then started to listen for events, we would have lost the events stored on the source database in the meantime. However, as we start the migration by listening for events on the source database, and then proceeding with the dump, we do not lose any of the events stored on the source database during that time.
The diagram below presents how such a kind of write anomaly could happen if we started dumping data before listening for Mongo Change Events.
Implementation details
Concurrency
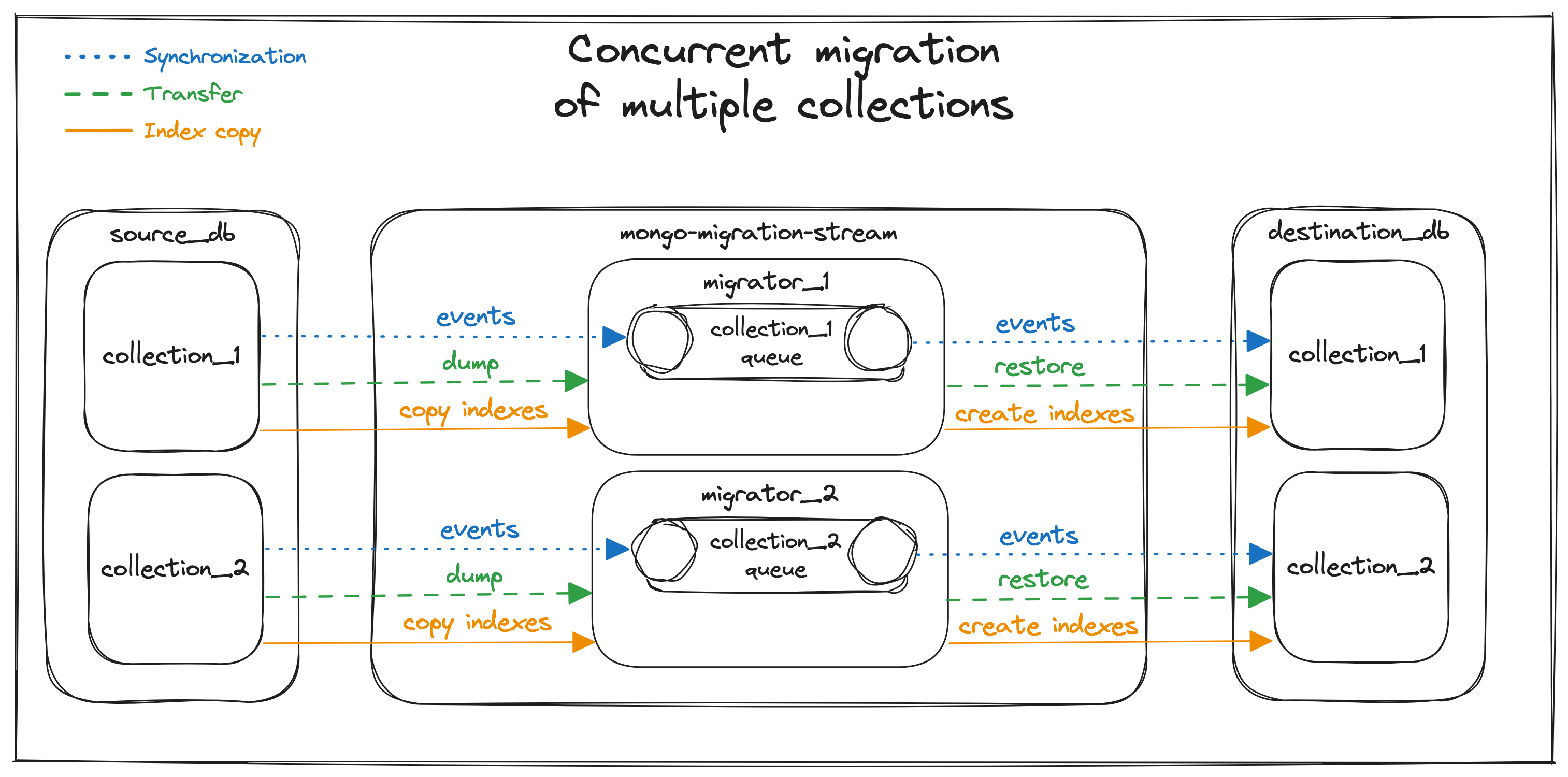
From the beginning we wanted to make mongo-migration-stream fast — we knew that it would need to cope with databases having more than 10k writes per second. As a result mongo-migration-stream parallelizes migration of one MongoDB database into independent migrations of collections. Each database migration consists of multiple little migrators — one migrator per collection in the database.
The transfer process is performed in parallel for each collection, in separate mongodump and mongorestore processes.
Synchronization process was also implemented concurrently — at the beginning of migration, each collection on source database is watched individually
using Mongo Change Streams with collection target.
All collections have their own separate queues in which Mongo Change Events are stored.
At the final phase of migration, each of these queues is processed independently.
Initial data transfer
To perform transfer of the database, we’re executing mongodump and mongorestore commands for each collection.
For that reason, machines on which mongo-migration-stream is running are required to have MongoDB Command Line Database Tools installed.
Dumping data from collection collectionName in source database can be achieved by running a command:
mongodump \
--uri "mongodb://mongo_rs36_1:36301,mongo_rs36_2:36302,mongo_rs36_3:36303/?replicaSet=replicaSet36" \
--db source \
--collection collectionName \
--out /home/user/mongomigrationstream/dumps \
--readPreference secondary
--username username \
--config /home/user/mongomigrationstream/password_config/dump.config \
--authenticationDatabase admin
Starting a mongodump process from Kotlin code is done with Java’s ProcessBuilder feature.
ProcessBuilder requires us to provide a process program and arguments in the form of a list of Strings.
We construct this list using prepareCommand function:
override fun prepareCommand(): List<String> = listOf(
mongoToolsPath + "mongodump",
"--uri", dbProperties.uri,
"--db", dbCollection.dbName,
"--collection", dbCollection.collectionName,
"--out", dumpPath,
"--readPreference", readPreference
) + credentialsIfNotNull(dbProperties.authenticationProperties, passwordConfigPath)
Having ProcessBuilder with properly configured list of process program and arguments, we’re ready to start a new process
using the start() function.
fun runCommand(command: Command): CommandResult {
val processBuilder = ProcessBuilder().command(command.prepareCommand()) // Configure ProcessBuilder with mongodump command in form of List<String>
currentProcess = processBuilder.start() // Start a new process
// ...
val exitCode = currentProcess.waitFor()
stopRunningCommand()
return CommandResult(exitCode)
}
An analogous approach is implemented in mongo-migration-stream to execute the mongorestore command.
Event queue
During the process of migration source database can constantly receive changes, which mongo-migration-stream is listening to with Mongo Change Streams. Events from the stream are saved in the queue for sending to the destination database at a later time. Currently mongo-migration-stream provides two implementations of the queue, where one implementation stores the data in RAM, while the other one persists the data to disk.
In-memory implementation can be used for databases with low traffic, or for testing purposes, or on machines with a sufficient amount of RAM (as events are stored as objects on the JVM heap).
// In-memory queue implementation
internal class InMemoryEventQueue<E> : EventQueue<E> {
private val queue = ConcurrentLinkedQueue<E>()
override fun offer(element: E): Boolean = queue.offer(element)
override fun poll(): E = queue.poll()
override fun peek(): E = queue.peek()
override fun size(): Int = queue.size
override fun removeAll() {
queue.removeAll { true }
}
}
In our production setup we decided to use a persistent event queue, which is implemented on top of BigQueue project. As BigQueue only allows enqueuing and dequeuing byte arrays, we had to implement serialization and deserialization of the data from the events.
// Persistent queue implementation
internal class BigQueueEventQueue<E : Serializable>(path: String, queueName: String) : EventQueue<E> {
private val queue = BigQueueImpl(path, queueName)
override fun offer(element: E): Boolean = queue.enqueue(element.toByteArray()).let { true }
override fun poll(): E = queue.dequeue().toE()
override fun peek(): E = queue.peek().toE()
override fun size(): Int = queue.size().toInt()
override fun removeAll() {
queue.removeAll()
queue.gc()
}
private fun E.toByteArray(): ByteArray = SerializationUtils.serialize(this)
private fun ByteArray.toE(): E = SerializationUtils.deserialize(this)
}
Migrating indexes
In early versions of mongo-migration-stream, to copy indexes from source collection to destination collection, we used
an index rebuilding feature from mongodump and mongorestore tools.
This feature works on the principle that the result of mongodump consists of both documents from the collection and definitions of indexes.
mongorestore can use those definitions to rebuild indexes on destination collection.
Unfortunately it occurred that rebuilding indexes on destination collection after transfer phase (before starting synchronization process)
with the mongorestore tool lengthened the entire mongorestore process, preventing us from emptying the queue in the meantime.
It resulted in a growing queue of events to synchronize, ending up with overall longer migration times and higher resources utilisation.
We’ve come to the conclusion, that we must rebuild indexes, while at the same time, keep sending events from the queue to destination collection.
To migrate indexes without blocking migration process, we implemented a solution which for each collection,
fetches all its indexes, and rebuilds them on destination collection.
Looking from the application perspective, we use getRawSourceIndexes function to fetch a list of Documents
(representing indexes definitions) from source collection,
and then recreate them on destination collection using createIndexOnDestinationCollection.
private fun getRawSourceIndexes(sourceToDestination: SourceToDestination): List<Document> =
sourceDb.getCollection(sourceToDestination.source.collectionName).listIndexes()
.toList()
.filterNot { it.get("key", Document::class.java) == Document().append("_id", 1) }
.map {
it.remove("ns")
it.remove("v")
it["background"] = true
it
}
private fun createIndexOnDestinationCollection(
sourceToDestination: SourceToDestination,
indexDefinition: Document
) {
destinationDb.runCommand(
Document().append("createIndexes", sourceToDestination.destination.collectionName)
.append("indexes", listOf(indexDefinition))
)
}
Our solution can rebuild indexes in both older and newer versions of MongoDB.
To support older MongoDB versions we specify { background: true } option, which does not block all operations on a given database during index creation.
In case where destination database is newer than or equal to MongoDB 4.2, the { background: true } option is ignored, and
optimized index build is used.
In both scenarios rebuilding indexes does not block synchronization process, improving overall migration times.
Verification of migration state
Throught mongo-migration-stream implementation we kept in mind that migrator user should be aware what’s happening within his/her migration. For that purpose mongo-migration-stream exposes data about migration in multiple different ways:
-
Logs — migrator logs all important information, so user can verify what’s going on,
-
Periodical checks — when all migrated collections are in synchronization process, migrator starts a periodical check for each collection, verifying if all the data has been migrated, making collection on destination database ready to use,
-
Metrics — various metrics about migration state are exposed through Micrometer.
On top of all that, each migrator internal state change emits an event to in—memory event bus. There are multiple types of events which mongo-migration-stream produces:
| Event type | When the event is emitted |
|---|---|
StartEvent |
Start of the migration |
SourceToLocalStartEvent |
Start watching for a collection specific Mongo Change Stream |
DumpStartEvent |
Start mongodump for a collection |
DumpUpdateEvent |
Each mongodump print to stdout |
DumpFinishEvent |
Finish mongodump for a collection |
RestoreStartEvent |
Start mongorestore for a collection |
RestoreUpdateEvent |
Each mongorestore print to stdout |
RestoreFinishEvent |
Finish mongorestore for a collection |
IndexRebuildStartEvent |
Start rebuilding indexes for a collection |
IndexRebuildFinishEvent |
Finish rebuilding indexes for a collection |
LocalToDestinationStartEvent |
Start sending events from queue to destination collection |
StopEvent |
Stop of the migration |
PauseEvent |
Pause of the migration |
ResumeEvent |
Resume of paused migration |
FailedEvent |
Fail of collection migration |
Application modules
mongo-migration-stream code was split into two separate modules:
mongo-migration-stream-coremodule which can be used as a library in JVM application,mongo-migration-stream-climodule which can be run as a standalone JAR.
mongo-migration-stream in production at Allegro
Since internal launch in January 2023, we have migrated more than a hundred production databases using mongo-migration-stream. The largest migrated collection stored more than one and a half billion documents. At its peak moments, migrator was synchronizing a collection which emitted about 4 thousand Mongo Change Events per second. During one of our migrations, one collection queue size reached almost one hundred million events. All of those events were later successfully synchronized into destination collection.
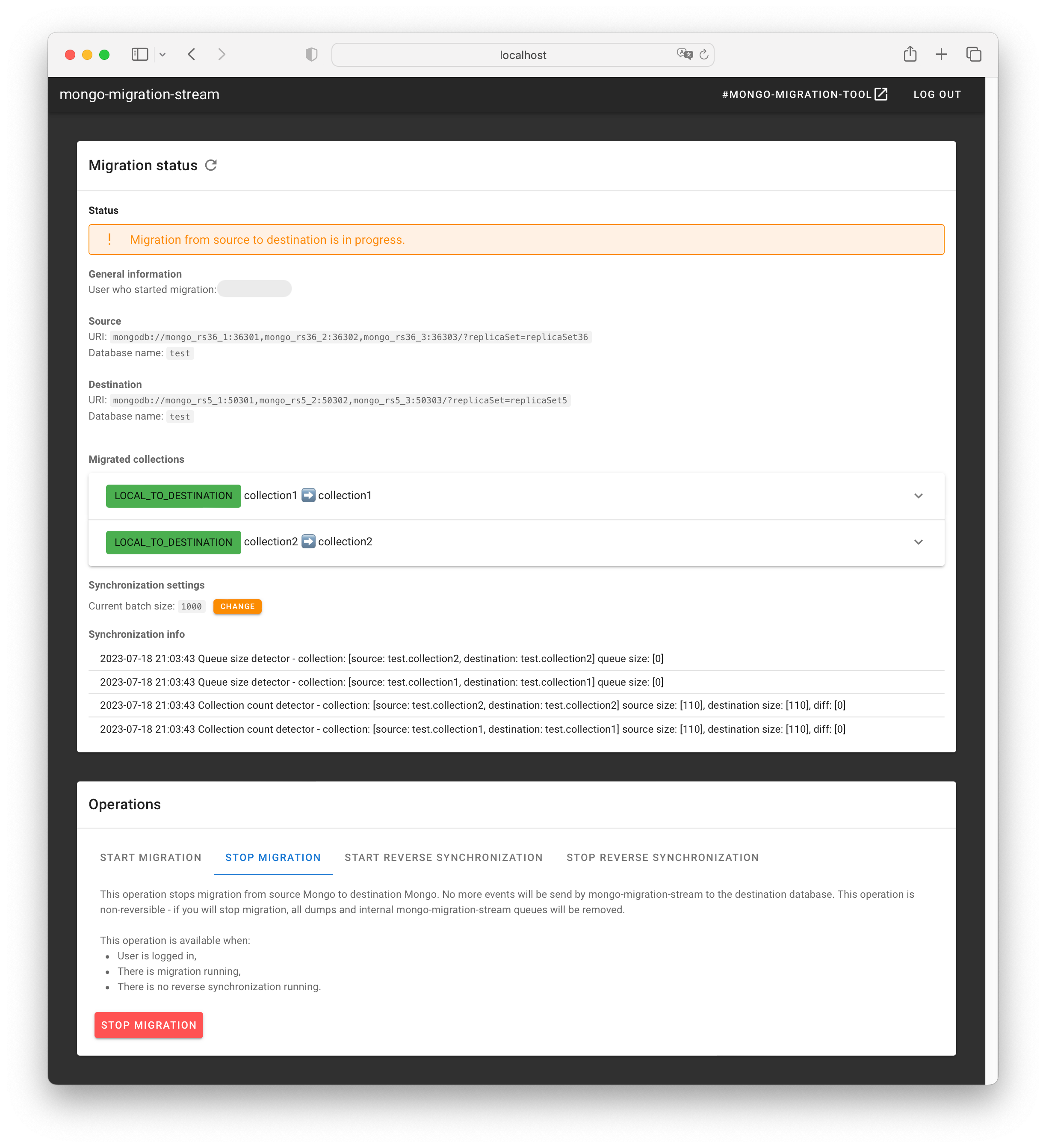
At Allegro we use mongo-migration-stream as a library in a Web application with graphical user interface. This approach allows Allegro engineers to manage database migrations on their own, without involving database team members. On the screenshot below you can see our Web application GUI during a migration.